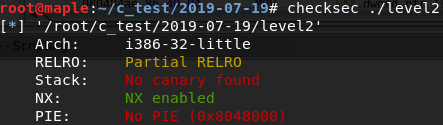
0x00 写在开头
曾几何时php一不小心闯入了我生活,php语法竟然和C语言那么莫名的相似,这是最初php给我的感受,当接触的php时间越来越多的时候,php也没有那般生涩难懂,但是偶尔一些的新的php 设计思想,也会思考许久,不知是从什么时候开始了php另一个世界。我想应该是从那次的类型转换开始的,"1e12"字符串类型在转化为数字类型变量时,不同的php版本下转换结果截然不同,有的就变成了数字1,有的却可以正常的识别为科学计数法10^12,在这个地方就已经悄悄的埋下了一枚种子。
到后来的使用php://filter/string.strip_tags/resource包含文件时为什么会出现SegmentFault,在HCTF2017上初识orange带来phar的metadata反序列化0day,溯源使用imap_open到底是如何绕过disable_function限制的,在WP5.0 RCE中mkdir的差异,到今年四月份在twitter看见的chdir 配合ini_set绕过open_basedir的限制。echo,eval 语法结构的分析,create_function的代码注入,各种各样的PHP内部的hook,php扩展的编写,到最近的SG的zend扩展加密....
这一路看来,我早已经陷入php的魅力无法自拔。不知道在这篇文章面前的你们,是否也曾有过像我那般想要领略php神秘内部的冲动?有些人却忘而生畏,无从下手。希望你们读完此篇,能点燃那颗微弱甚至熄灭的向往,或者是在你们的冲动上再加一把火。读完之后若有所感,便是对本文最大的肯定了。
0x01 概述
php 是一门针对web的专属语言,但是随着这么长时间发展,其实已经可以用php做很多事了,甚至语法结构的复杂度在趋近于java,还有即将出来的JIT,php的未来变的很难说。
尽管如此php还是一门解释型语言。解释型语言相对于静态编译型语言最大的特点就是他有一个特殊的解释器。利用解释器去执行相应的操作,例如php代码是不会再去被翻译成机器语言再去执行的。
例如在php 中
那么在相应的解释器里面比如存在,一个与之相对应的解释过程,可能是一个函数例如
1 2 3 int add (int a, int b) return a+b; }
在这里面就仅需要调用这个add函数去解释这个加法表达式的赋值过程。那么问题来了php的解释器是怎样的一种呈现过程呢?由此引出php的核心ZendVM(虚拟机)。
如果想要弄清楚我们写的phpCode最后是如何被正确的运行的,就需要去了解Zend VM到底做了什么?也正是因为ZendVM赋予了php跨平台的能力。所以相同的phpCode可以不需要修改就运行在处于不同平台的解释器上。这一点需要知道。
其实虚拟机大多都一样,都是模拟了真实机器处理过程。不同是的运算符,数据类型的定义存在差异。在具体的语法逻辑结构上,大多都大同小异,例如if,switch,for这些流程控制,还有在函数的调用上。所以在探究一个虚拟机的内部结构时,你需要有一个明确的目标:
虚拟机内部用来描述整个执行过程的指令集。
单个指令对应的解释过程。
清楚以上两点,再来探究ZendVM。同样ZendVM有编译和执行两个模块。编译过程就是将phpCode编译为ZendVM内部定义好的一条一条的指令集合,再通过执行器去一步一步的解释指令集合。
单条的指令在php里面被称为"opline",指令的定义内容可以结合汇编的相关知识理解。例如汇编语言中
其中有两个关键字add和jmp,这是汇编语言内部定义的指令集合中的两个。同样在php也有像类似的指令关键字叫做opcode,指令关键字后面是改指令处理的数据,简称为操作数。单条指令可能有两个操作数op1,op2,也可能只有一个op1,也可能存在一个操作数都没有的情况,但至多只有两个操作数。那么指令是如何使用操作数,首先必须知道它的类型和具体的数据内容。这里可以具体看一下ZendVM内部定义的单条opline结构:
Opline
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct _zend_op { const void *handler; znode_op op1; znode_op op2; znode_op result; uint32_t extended_value; uint32_t lineno; zend_uchar opcode; zend_uchar op1_type; zend_uchar op2_type; zend_uchar result_type; }; typedef struct _zend_op zend_op ;
可以看到不仅有两个操作数的op1和op2的定义,还有一个result变量,这个是变量是标识单条opline执行的返回值,当出现使用函数返回值赋值时,多个变量连续赋值,变量赋值出现在if判断语句里面时,在这几种情况下result变量就会被用到。
如果有想看到底定义了哪些opcode的同学,可以在zend/zend_vm_opcodes.h 里面去看,本文使用的php版本为7.4.0-dev,一共有199条opcode。
下面简单解释一下,zend_op这个结构里面znode_op,zend_uchar这些结构的含义。可以看到一个操作数是有前面这两种结构定义的相关变量,分别指向的是操作数内容和操作数类型,操作数的类型可以分为下面5种
1 2 3 4 5 #define IS_UNUSED 0 #define IS_CONST (1<<0) #define IS_TMP_VAR (1<<1) #define IS_VAR (1<<2) #define IS_CV (1<<3)
UNUSED 表示这个操作数并未使用
CONST 表示操作数类型是常量。
TMP_VAR为临时变量,是一种中间变量。出现再复杂表达式计算的时候,比如在进行字符串拼接(双常量字符串拼接的时候是没有临时变量的)。
VAR 一种PHP内的变量,大多数情况下表示的是单条opline的返回值,但是并没有显式的表现出来,列如在if判断语句包含某个函数的返回值,if(random()){},在这种情况下random()的返回值就是VAR变量类型。
CV变量,是在php代码里面显式的定义的出来的变量例如$a等。
Znode_op
接下来是操作数的内容znode_op
1 2 3 4 5 6 7 8 9 10 11 12 13 14 typedef union _znode_op { uint32_t constant; uint32_t var; uint32_t num; uint32_t opline_num; #if ZEND_USE_ABS_JMP_ADDR zend_op *jmp_addr; #else uint32_t jmp_offset; #endif #if ZEND_USE_ABS_CONST_ADDR zval *zv; #endif } znode_op;
znode_op其实一个union结构。其实可以分为两种情况来谈,相对寻址和绝对寻址。从定义的宏分支里面也可以看出来。这里就需要先介绍一下,关于opline里面的操作数是在哪分配的。先引出我们的zend_op_array
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 struct _zend_op_array { zend_uchar type; zend_uchar arg_flags[3 ]; uint32_t fn_flags; zend_string *function_name; zend_class_entry *scope; zend_function *prototype; uint32_t num_args; uint32_t required_num_args; zend_arg_info *arg_info; int cache_size; int last_var; uint32_t T; uint32_t last; zend_op *opcodes; ZEND_MAP_PTR_DEF(void **, run_time_cache); ZEND_MAP_PTR_DEF(HashTable *, static_variables_ptr); HashTable *static_variables; zend_string **vars; uint32_t *refcount; int last_live_range; int last_try_catch; zend_live_range *live_range; zend_try_catch_element *try_catch_array; zend_string *filename; uint32_t line_start; uint32_t line_end; zend_string *doc_comment; int last_literal; zval *literals; void *reserved[ZEND_MAX_RESERVED_RESOURCES]; };
zend_op_array是包含编译过程中产生的所有单个opline的集合,不仅仅包含opline的集合数组同样,还含有其他在编译过程动态生成的关键数据,这里先简单介绍一下其中几种。
vars变量包含CV变量名的指针数组。CV变量前面也已经提到过了就是,由$定义的php变量。这里的vars相当于一张CV变量名组成的表,是不存在重复变量名的,对应的变量值存储在另外一个结构上。
last_var 表示最后一个CV变量的序号。其实也可以代表CV变量的数量。
literals 是存储编译过程中产生的常量数组。根据编译过程中依次出现的顺序,存放在该数组中
last_literal表示当前储存的常量的数量。
T 表示的是TMP_VAR和VAR的数量。
Zend_execute_data
以上就是操作数部分信息储存的地方。可以看到在zend_op_array里面仅分配了CV变量名数组,但是这里面并没有储存CV变量值的地方,同样TMP_VAR和VAR变量亦是如此,也只有一个简单数量统计。对应的变量值储存在另外一个结构上,那么他们的具体的值应该在什么样的结构上分配呢?接着又引出了zend_execute_data结构。
1 2 3 4 5 6 7 8 9 10 11 12 struct _zend_execute_data { const zend_op *opline; zend_execute_data *call; zval *return_value; zend_function *func; zval This; zend_execute_data *prev_execute_data; zend_array *symbol_table; #if ZEND_EX_USE_RUN_TIME_CACHE void **run_time_cache; #endif };
zend_execute_data相当于在执行编译oplines的Context(上下文),是通过具体的某个zend_op_array的结构信息初始化产生的。所以一个zend_execute_data对应一个zend_op_array,这个结构用来存储在解释运行过程产生的局部变量,当前执行的opline,上下文之间调用的关系,调用者的信息,符号表等。所以我们想要知道的CV变量,TMP_VAR, VAR变量其实是分配在这个结构上面的,而且还是动态分配紧挨在这个结构后面的。接下来看一看这些变量是怎么依附在这个结构后面的。
关于分配顺序,首先是分配CV变量,然后就是依次出现的VAR,TMP_VAR变量。关于在动态分析取这个局部变量区里面的值时,需要注意几点,网上基本都是千篇一律的 (zval *)(((char *)(execute_data))+96)这样去取第一个值对吧,其实有时候你发现你取的根本不正确,需要注意的是:
sizeof(zend_execute_data) 需要注意的是你用的php版本中zend_execute_data 结构的大小,其实有时候并不是96,我这里就是72。动态分配的变量在zend_execute_data结构的末尾,所以你需要提前知道这个结构的大小。
如果你傻乎乎现在又+72,你发现取的是不对的,明明是在zend_data结尾取的值,为什么还是还不对?这过程需要注意的是,这中间存在一个16的对齐过程,如下,zend_execute_data分配的大小是按照sizeof(zval)的整数倍来分配的,即16对齐。
1 2 3 4 5 6 7 8 9 10 11 12 #define ZEND_CALL_FRAME_SLOT \ ((int )((ZEND_MM_ALIGNED_SIZE(sizeof (zend_execute_data)) + ZEND_MM_ALIGNED_SIZE(sizeof (zval)) - 1 ) / ZEND_MM_ALIGNED_SIZE(sizeof (zval)))) static zend_always_inline uint32_t zend_vm_calc_used_stack (uint32_t num_args, zend_function *func) uint32_t used_stack = ZEND_CALL_FRAME_SLOT + num_args; if (EXPECTED(ZEND_USER_CODE(func->type))) { used_stack += func->op_array.last_var + func->op_array.T - MIN(func->op_array.num_args, num_args); } return used_stack * sizeof (zval); }
综上大概明白了CV变量,TMP_VAR变量,VAR变量储存位置,再来谈opline中操作数内容如何获取。
可以通过znode_op.var , znode_op.constant 来相对寻址,var代表是CV,TMP_VAR,VAR相对位置,即这里就是0x50,0x60,0x70这样相对于zend_execute_data结构起始地址。一般情况下是这样表示的
同样也可以直接寻址直接用zval *指针寻址
在jmp 跳转里面也存在直接跳转和间接跳转。
你会发现这里面没有讲到opline里面handler字段,关于opline中 handler的具体细节会在后面详细介绍。概要也差不多介绍到这里,主要需要对这些经常用到结构有一个印象(zend_op,znode, opcode_array,execute_data)。下面就开始具体的介绍细节的实现过程,这些结构具体应用在哪些地方。
0x02 编译过程
整个编译过程是整个PHP代码范围的从开始到结束,在PHP里面没有main函数一说,直接从头编译到尾,其实从到开始到结尾已经算是main函数的范围了,除了函数,类的定义以外。编译的结果是一条一条对应的opline集合。编译原理其实和大多数语言的编译器一样,都需要进行词法分析和语法分析。PHP开始阶段也是如此,在php7.0的版本中在这个两个步骤之后增加了一步生成AST语法树,目的是将PHP的编译过程和执行过程解耦。抽象语法树就处于了编译器和执行器的中间,如果只需要调整相关的语法规则,仅仅需要修改编译器生成抽象语法树的相关规则就行,抽象语法树生成的opline不变。相反你修改新的opcode但是语法规则并不变,只需要修改抽象语法树编译成opline的过程即可。
词法分析过程就是一个把PHP代码拆分的过程,按照定义好的token去匹配分割。词法分析就是将分割出来的token再按照语法规则重新组合到一起。PHP内词法分析和语法分析分别使用的是re2c和yacc来完成的。其实准确来说一个应该是re2c和bison。
在研究和探索这个方面的同学一定要注意,不要去细看经过re2c和bison预处理生成的.c文件。这部分都是自动生成,看起来其实有点费时费力也毫无意义。但是你可以对比起来看,最重要是明白re2c和yacc的语法,如果你想要了解这个过程真正做了什么。
re2c
首先从大的方向来看re2c就是一个用正则来分割token的东西,将我们的php代码分割一个个在php代码里面会用到的关键字或者是关键符号,如果你想快速的了解是如何分割token的,其实也不用去看re2c的处理过程。可直接用php 的内置函数token_get_all,通过传入指定的php代码,将会指定的token数组,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?php var_dump(token_get_all('<?php print(1);' )); array (6 ) { [0 ] => array (3 ) { [0 ] => int (379 ) [1 ] => string (6 ) "<?php " [2 ] => int (1 ) } [1 ] => array (3 ) { [0 ] => int (266 ) [1 ] => string (5 ) "print" [2 ] => int (1 ) } [2 ] => string (1 ) "(" [3 ] => array (3 ) { [0 ] => int (317 ) [1 ] => string (1 ) "1" [2 ] => int (1 ) } [4 ] => string (1 ) ")" [5 ] => string (1 ) ";" }
可以看到是返回的token数组又是一个一个的数组单元,其中依次返回是token对应的整数值,token内容,行号。注意到其中有几个token ();并不是以数组返回的,而是是直接返回的内容,这里是因为;:,.\[\]()|^&+-/*=%!~$<>?@这样简单的单字符都是以原字符返回。如果想要得到token的标识符名称,可以通过token_name内置函数来转换。如果有同学知道php-parser的话,其实php-parser中的lexer也是应用这两个内置函数,php-parser是一个很不错的工具,可以解决绝大部分在php层面上的混淆,后面会简单的介绍一下。
具体去看看用re2c写的语法,其实你会发现其实可以解决很多在你心中的困惑,php里面对应的lexer函数是lex_scan,re2c核心的语法也在其中。
在这里我挑几处有意思的语法讲一讲,re2c并不是一个全自动的词法分析器,用户需要给它提供一些接口,这里的yyfill就是一个动态填充输入值的接口,在这里表示不需要在分割的过程中动态分配输入值,即不要考虑在扫描的过程中填充用来继续被分割的值,因为在获取文件内容的时候,是一次性把文件的全部内容映射到了内存中。有兴趣的同学可以去看一看open_file_for_scanning()中的具体实现过程。
re2c语法看起来是不是和正则特别像,其实就是正则,只不过是通过C中goto 和 switch 或者if语法组合起来呈现。从定义的字面类型来看,整形,浮点型,指数表示,十六进制,二进制等这些都是php可能会用到的数据类型,其中定义了LABEL类型,可能有些同学就不知道这是用来表示什么的,其实这就是php里面变量名的定义,除了不能用数字开头以外,你会发现php变量名竟然也可以用[\x80-\xff]这些ascii里面的扩展字符来定义变量名,其实这个东西已经应用到了一些php的变量名混淆上,你有时候可能会发现有些变量名根本不可读,可能就采用扩展字符来重新定义。细心的你可能会发现,在上面一行定义16进制和2进制这些转义类型的时候,用的是双引号,用双引号括起来的字符串,在re2c的语法里面表示是对大小写敏感,为什么这里是双引号呢?在php里面0Xff这样表示也是可以的,这就涉及到re2c预处理时候的传参了,关于re2c和bison在使用过程中指定的参数可以在/php-src/Zend/Makefile.fragments找到。里面re2c的参数选项里面多了一个--case-inverted大小写敏感的翻转,即现在是双引号表示对大小写不敏感。在后面也可看到是php对关键字的大小写都是不敏感的。
接着后面就是一个规则对应一个处理过程,一般的处理过程就是匹配规则,返回对应的token标识符。有一些会做特殊处理例如双引号单引号等这些包裹字符串的字符可能不会返回单字符,可能会接着扫描至完整的字符串,返回常量的token标志。可能有同学不理解每一个规则之前都有一部分用<>包裹的内容:
1 2 3 4 5 6 7 8 9 10 11 12 <INITIAL>"<?php" ([ \t]|{NEWLINE}) { HANDLE_NEWLINE(yytext[yyleng-1 ]); BEGIN(ST_IN_SCRIPTING); if (PARSER_MODE()) { SKIP_TOKEN(T_OPEN_TAG); } RETURN_TOKEN(T_OPEN_TAG); } <ST_IN_SCRIPTING>"function" { RETURN_TOKEN(T_FUNCTION); }
这一部分表示lexer 当前状态,开始是<INITIAL>初始化状态,需要找到php代码的起始符,接着进入<ST_IN_SCRIPTING>状态,才会接着去扫描php代码内的token,相当于一种lexer的嵌套。lex_scan有两种返回方式,token的标识符会通过lex_token函数值返回。一些token仅需要返回token标识符就就够了,有一些需要返回token对应的具体的内容,内容的返回值是以抽象语法数的节点类型返回,通过在调用lex_scan时传递的elem参数,elem是个union结构
1 2 3 4 5 6 typedef union _zend_parser_stack_elem { zend_ast *ast; zend_string *str; zend_ulong num; } zend_parser_stack_elem;
把分割出来的token放到后面语法分析用来存储token的栈中,这个类型在yyac匹配语法时的指定为YYSTYPE,在匹配语法会根据定义的%type,转化为指定zend_parser_stack_elem中的一种类型。到此re2c也再无神秘之处,理一下大概可分为,正则规则对应处理过程,在处理的过程中一定会返回token,可能会切换lexer的状态或者返回具体的token内容。其中还有一个SCNG宏,是对定义的scanner_global全局变量的取值操作。这个变量结构如下包含了lexer当前处理的指针位置,状态,结束指针,记录的最后一次token位置等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 struct _zend_php_scanner_globals { zend_file_handle *yy_in; zend_file_handle *yy_out; unsigned int yy_leng; unsigned char *yy_start; unsigned char *yy_text; unsigned char *yy_cursor; unsigned char *yy_marker; unsigned char *yy_limit; int yy_state; zend_stack state_stack; zend_ptr_stack heredoc_label_stack; zend_bool heredoc_scan_ahead; int heredoc_indentation; zend_bool heredoc_indentation_uses_spaces; unsigned char *script_org; size_t script_org_size; unsigned char *script_filtered; size_t script_filtered_size; zend_encoding_filter input_filter; zend_encoding_filter output_filter; const zend_encoding *script_encoding; int scanned_string_len; void (*on_event)(zend_php_scanner_event event, int token, int line, void *context); void *on_event_context; };
yacc && bison
接下来就是yacc语法分析器,yacc对应的功能函数在php里面为zendparse(),这个函数其实预处理自动生成的,在这个函数通过不断的调用lex_scan返回token,根据定义的语法规则动态的生成抽象语法数,挑出一些有代表性的yacc语法规则来描述一下
1 2 3 4 5 6 7 8 %left '|' %left '^' %left '&' %nonassoc T_IS_EQUAL T_IS_NOT_EQUAL T_IS_IDENTICAL T_IS_NOT_IDENTICAL T_SPACESHIP %nonassoc '<' T_IS_SMALLER_OR_EQUAL '>' T_IS_GREATER_OR_EQUAL %left T_SL T_SR %left '+' '-' '.' %left '*' '/' '%'
这里定义的是运算符类的token的优先级和结合性。后定义的优先级要高,在同行定义的优先级相同,结合性就看是%left还是%right,%left代表从左到右,同理%right反之,其实结合性就相当于同级之间的优先级。这些都会在yacc状态机里面体现出来。
1 2 3 4 5 6 7 8 9 %token <ast> T_LNUMBER "integer number (T_LNUMBER)" %token <ast> T_DNUMBER "floating-point number (T_DNUMBER)" %token <ast> T_STRING "identifier (T_STRING)" %token <ast> T_VARIABLE "variable (T_VARIABLE)" %token <ast> T_INLINE_HTML %token <ast> T_ENCAPSED_AND_WHITESPACE "quoted-string and whitespace (T_ENCAPSED_AND_WHITESPACE)" %token <ast> T_CONSTANT_ENCAPSED_STRING "quoted-string (T_CONSTANT_ENCAPSED_STRING)" %token <ast> T_STRING_VARNAME "variable name (T_STRING_VARNAME)" %token <ast> T_NUM_STRING "number (T_NUM_STRING)"
%token开头定义的表示语法规则里面会用到的token,也是语法规则的终结符。其中<ast> 表示在使用token时候会进行类型的转换,所有的token类型定义在YYSTYPE中,这个结构前面也说过了是一个联合体,在yacc自动的生成yyparse函数下,获取的token对应的内容会保留在yylval中,所以在使用的时候,会进行yylval.ast类似的操作。
1 2 3 4 5 6 7 8 9 10 11 12 %type <ast> top_statement namespace_name name statement function_declaration_statement %type <ast> class_declaration_statement trait_declaration_statement %type <ast> interface_declaration_statement interface_extends_list %% start: top_statement_list { CG(ast) = $1 ; } ; top_statement_list: top_statement_list top_statement { $$ = zend_ast_list_add($1 , $2 ); } | { $$ = zend_ast_create_list(0 , ZEND_AST_STMT_LIST); } ;
%type定义就是非终结符,非终结字符常常是自己和token组合在一起的递归嵌套符。同样它也有类型的定义<ast>。后面就是描述非终结字符是如何嵌套的,有一个特殊的start节点,yacc在开始扫描语法的规则的时候只关注它,相当于入口点。可以看到起始是以top_statement_list标识符,它是可以为空的,所以每次语法扫描的第一步就是CG(ast) = zend_ast_create_list(0, ZEND_AST_STMT_LIST),建立一个根节点,但是这个根节点也不做。如果你真的想看看yacc内部扫描语法的,不要去看经过bison预处理之后的.c文件,同级目录下有一个.output后缀相同文件名的文件,里面描述了yacc里面的状态机是如何工作的。可能还是有点看不懂,重新拿bison处理一遍,把trace打开,再重新把php编译一遍,再用php运行代码的过程中就会输出状态机的状态和转移。
1 bison -p zend -v -d -t $(srcdir)/zend_language_parser.y -o zend_language_parser.c
最好用bison的版本和你在看php版本使用的相同,在zend_language_parser.c中开头会显示bison的版本,翻译完成替换原来的zend_language_parser.c 和 zend_language_parser.h,这个时候需要再处理一下,再加点东西,在输出debug过程中,它不会自己输出相对于的token的值,因为前面说道过了token的值类型是zend_parser_stack_elem,是我们自定义的,同样如果我们想要打印token具体的值,需要自己提供接口,yacc也一个宏YYPRINT,在这里可以不用为它这个宏提供个函数。如果你只想看每次从lex_scan拿来的token对应的内容是什么,可以这样写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static void yy_symbol_print (FILE *yyoutput, int yytype, YYSTYPE const * const yyvaluep) { YYFPRINTF (yyoutput, "%s %s (" , yytype < YYNTOKENS ? "token" : "nterm" , yytname[yytype]); char *ztext = LANG_SCNG(yy_text); unsigned int zlen = LANG_SCNG(yy_leng); unsigned int i = 0 ; for (i;i<zlen;i++){ php_printf("%c" ,*(ztext+i)); }+ YYFPRINTF (yyoutput, ")" ); }
添加里面其中一段代码就行,把yy_symbol_value_print注释掉,这是在用bison预处理之后在zend_language_parser.c里面添加的哦。你会发现这样做,不仅不仅在从lex_scan拿到token会用到这个函数,后面语法规则匹配以后也会用这个函数来输出匹配字符的token值,这样会导致一直输出同样的token值,直到下次再次从lex_scan中拿到新token值。再稍微改一下,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static void yy_symbol_value_print (FILE *yyoutput, int yytype, YYSTYPE const * const yyvaluep) { FILE *yyo = yyoutput; YYUSE (yyo); if (!yyvaluep) return ; # ifdef YYPRINT if (yytype < YYNTOKENS){ zval sym; sym =((zend_ast_zval *)(yyvaluep->ast))->val; switch (yytoknum[yytype]){ case 317 : php_printf("%d" ,sym.value.lval); break ; case 325 : if (sym.u1.v.type==IS_LONG){ php_printf("%d" ,sym.value.lval); break ; } case 321 : case 323 : for (int i=0 ;i<(sym.value.str)->len;i++){ php_printf("%c" ,*(((sym.value.str)->val)+i)); } break ; case 318 : php_printf("%d" ,sym.value.dval); break ; default : php_printf("%d" ,yytoknum[yytype]); } } # endif YYUSE (yytype); }
注意这次改的地方是yy_symbol_value_print,记得要在前面在简单定义一下YYPRINT这个宏,因为需要yytoken这个映射表,这里根据映射表返回的token数字量,token的数字量在zend_language_parser.h定义,判断token类型,可以看到带返回值的token其实也只有三种,IS_SRTING,IS_LONG,IS_DOUBLE。字符串类型上出现了3个不一样的token,323就是字符串常量,321也好理解内联的php标签外的html字符串。这个325处T_NUM_STRING有点意思,我这地方发现了php一个一直存在的语法错误?可以看到其实这个token的返回值zval有两种不同的类型整形和字符串。具体的我们去看看re2c是怎么匹配返回这个token的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <ST_VAR_OFFSET>[0 ]|([1 -9 ][0 -9 ]*) { if (yyleng < MAX_LENGTH_OF_LONG - 1 || (yyleng == MAX_LENGTH_OF_LONG - 1 && strcmp (yytext, long_min_digits) < 0 )) { char *end; errno = 0 ; ZVAL_LONG(zendlval, ZEND_STRTOL(yytext, &end, 10 )); if (errno == ERANGE) { goto string ; } ZEND_ASSERT(end == yytext + yyleng); } else { string : ZVAL_STRINGL(zendlval, yytext, yyleng); } RETURN_TOKEN_WITH_VAL(T_NUM_STRING); } <ST_VAR_OFFSET>{LNUM}|{HNUM}|{BNUM} { if (yyleng == 1 ) { ZVAL_INTERNED_STR(zendlval, ZSTR_CHAR((zend_uchar)*(yytext))); } else { ZVAL_STRINGL(zendlval, yytext, yyleng); } RETURN_TOKEN_WITH_VAL(T_NUM_STRING); } <ST_DOUBLE_QUOTES,ST_HEREDOC,ST_BACKQUOTE>"$" {LABEL}"[" { yyless(yyleng - 1 ); yy_push_state(ST_VAR_OFFSET); RETURN_TOKEN_WITH_STR(T_VARIABLE, 1 ); }
可以看到匹配返回这个token必须得在"$a[offset]"得在这种类似的情况才行,而且得在双引号或者<<<或者反引号的包裹下,就是能进行字符串转义。在匹配offset内容的时候,第一条规则是匹配10进制的纯数字,第二条规则是匹配0,0x,0b这样开头不同进制的数字类型。这样看来是比较合理的,在offset的选择上是支持不同进制的,但是在处理上确是不一样的。例如我下面的PHP代码
1 2 3 <?php $a ="123456" ;echo "$a [0x2]" ;
在语法上是通过的,但是出现结果确是不一样的。对应的opcode为FETCH_DIM_R !0 , '0x2',操作数1是CV变量,操作数为CONST字面量,找到相应的hanlder
1 ZEND_FETCH_DIM_R_SPEC_CV_CONST_HANDLER()
这里我不再累赘,只看最后的处理,具体的调用栈如下
1 2 3 4 5 6 7 8 9 10 #0 is_numeric_string (str=0x7ffff5402b58 "0x2", length=0x3, lval=0x0, dval=0x0, allow_errors=0xffffffff) at /root/php-src/Zend/zend_operators.h:142 #1 0x0000555555b99d9b in zend_fetch_dimension_address_read (result=0x7ffff541f090, container=0x7ffff541f070, dim=0x7ffff54824b0, dim_type=0x8, type=0x0, support_strings=0x1, slow=0x1) at /root/php-src/Zend/zend_execute.c:1882 #2 0x0000555555b9a285 in zend_fetch_dimension_address_read_R_slow (container=0x7ffff541f070, dim=0x7ffff54824b0) at /root/php-src/Zend/zend_execute.c:1971 #3 0x0000555555bede6a in ZEND_FETCH_DIM_R_SPEC_CV_CONST_HANDLER () at /root/php-src/Zend/zend_vm_execute.h:39187 #4 0x0000555555c0a694 in execute_ex (ex=0x7ffff541f020) at /root/php-src/Zend/zend_vm_execute.h:59035 #5 0x0000555555c0b971 in zend_execute (op_array=0x7ffff5482300, return_value=0x0) at /root/php-src/Zend/zend_vm_execute.h:60223 #6 0x0000555555b3a65d in zend_execute_scripts (type=0x8, retval=0x0, file_count=0x3) at /root/php-src/Zend/zend.c:1608 #7 0x0000555555aaa5a7 in php_execute_script (primary_file=0x7fffffffdd80) at /root/php-src/main/main.c:2643 #8 0x0000555555c0e3f9 in do_cli (argc=0x2, argv=0x55555654b060) at /root/php-src/sapi/cli/php_cli.c:997 #9 0x0000555555c0f379 in main (argc=0x2, argv=0x55555654b060) at /root/php-src/sapi/cli/php_cli.c:1390
最后是用is_numeric_string处理的我们的0x2偏移量,这个过程竟然只是一个php内部弱类型转换,从字符串到数值的类型转换,也就是说并不会对除10进制以外的数字变量进行转换。其他进制的数字串永远置零,那在语法上为什么还要匹配呢? php内部是有一个zend_strtod,却并没有在此处使用,明显的handler没有与语法对应上。php7.0在此处会给出警告,5.x版本不会给警告,但是结果依然都是错的。。。
上面相当于一个小插曲。yacc和re2c的介绍到这里也差不多了,也应该可以上手改一改语法了吧,在这里再讲一个有趣的语法结构print,我不知道有多少人看过鸟哥博客那段
1 print (1 ) && print (2 ) && print (3 ) && print (4 );
在不运行之前,你是否知道它的结果?你可以先不看下面的解答,先自己想想为什么会这样?
其实这个问题需要在语法分析这个阶段来看,可以先去yacc里面关于print的语法结构。
1 expr : T_PRINT expr { $$ = zend_ast_create(ZEND_AST_PRINT, $2); }
可以看到T_PRINT 是在expr递归的语法里面的,T_PRINT左边是expr,无论多么复杂最后都会递归成最后一个expr,并且T_BOOLEAN_AND (&&)优先级 大于 T_PRINT,且T_BOOLEAN_AND (&&)结合性是从左到右。
1 2 3 4 5 6 7 8 9 10 11 停止递归的点 expr1 : print (4) // expr:T_PRINT expr:scalar expr2 : 3 && expr1 // expr: expr '&&' expr expr3 : print expr2 // expr:T_PRINT expr expr4 : 2 && expr2 // expr:expr '&&' expr expr5 :print expr4 // expr:T_PRINT expr expr6 : 1 && expr5 // expr:expr '&&' expr expr7 : print expr6 //expr: T_PRINT expr statement1 : expr7 ; // statement: expr ';' top_statement1: statement1 // op_statement : statement top_statement_list: top_statement_list top_statement1 // zend_ast_list_add($1, $2);
简单的写了一遍yacc状态机走的过程,现在看起来应该再清晰不过了吧。print这个语法结构应该是最像function的一个结构。如果有兴趣也可以去分析分析echo,include 这些语法结构。
yacc和re2c到这里真的就结束了。抽象语法树其实是和它们耦合在一起的,虽然把编译器和执行器隔开了。re2c在返回的token对应的值的时候,就是以抽象语法树节点返回的。再通过yacc语法分析进一步建立完整的抽象语法树。
0X03 抽象语法树AST
通用的普通节点为:
1 2 3 4 5 6 struct _zend_ast { zend_ast_kind kind; zend_ast_attr attr; uint32_t lineno; zend_ast *child[1 ]; };
注意这个的child[1],并不是表示是一个节点,类似于zval_string里面的val[1],节点地址连续分配在zend_ast结构末尾。根据 kind 类型转换为其他类型节点,具体的类型和对应的结构在/Zend/zend_ast.h里面定义。常用的下面两个节点类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct _zend_ast_list { zend_ast_kind kind; zend_ast_attr attr; uint32_t lineno; uint32_t children; zend_ast *child[1 ]; } zend_ast_list; typedef struct _zend_ast_zval { zend_ast_kind kind; zend_ast_attr attr; zval val; } zend_ast_zval;
抽象语法的节点类型,也没什么特别的。前面也说提到过整个抽象语法树根节点zend_ast_stmt_list定义在CG(ast),中,CG是个访问编译全局变量的宏。有的同学可能会想看看既然是抽象语法树,肯定想看一看它在视图上是怎么呈现的,有办法。这里分享一个将php-parser处理过得到的抽象语法树可视化的东西。 https://github.com/ircmaxell/php-ast-visualizer 原本想自己写个扩展来动态显示抽象语法树,意外看到这个工具其实也没什么必要了。抽象语法数的建立是php静态分析里面重要的一环。
0x04 抽象语法树2Oplines
接下来就是如何将抽象语法数如何编译成我们期待已久的opline。这也是解释型语言和静态编译型语言不同的一点,编译出来的不是汇编语言,而是ZendVM可以识别的中间指令。前面也简单解释了一遍opline,一条opline和汇编语言类似,指令标识符opcode,操作数1和操作2。 编译抽象语法树发生在yacc的 zendparse()结束之后,同样在zend_compile里面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 if (!zendparse()) { int last_lineno = CG(zend_lineno); zend_file_context original_file_context; zend_oparray_context original_oparray_context; zend_op_array *original_active_op_array = CG(active_op_array); op_array = emalloc(sizeof (zend_op_array)); init_op_array(op_array, type, INITIAL_OP_ARRAY_SIZE); CG(active_op_array) = op_array; op_array->fn_flags |= ZEND_ACC_HEAP_RT_CACHE; if (zend_ast_process) { zend_ast_process(CG(ast)); } zend_file_context_begin(&original_file_context); zend_oparray_context_begin(&original_oparray_context); zend_compile_top_stmt(CG(ast)); CG(zend_lineno) = last_lineno; zend_emit_final_return(type == ZEND_USER_FUNCTION); op_array->line_start = 1 ; op_array->line_end = last_lineno; pass_two(op_array); zend_oparray_context_end(&original_oparray_context); zend_file_context_end(&original_file_context); CG(active_op_array) = original_active_op_array; }
开始正常的流程的,给op_array 分配内存,初始化,让CG(active_op_array)指向当前的op_array,zend_ast_process是个扩展的hook点,如果你想要对抽象语法树做一些自定义的东西,比如我先前把ast输出,就可以在此处做文章。
最主要的还是来看看是如何遍历抽象语法节点一步一步来编译成opcode,进入zend_compile_top_stmt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void zend_compile_top_stmt (zend_ast *ast) if (!ast) { return ; } if (ast->kind == ZEND_AST_STMT_LIST) { zend_ast_list *list = zend_ast_get_list(ast); uint32_t i; for (i = 0 ; i < list ->children; ++i) { zend_compile_top_stmt(list ->child[i]); } return ; } ...
判断节点如果为ZEND_AST_STMT_LIST,则再递归编译子节点,前面说过ZEND_AST_STMT_LIST是一种什么也不做的列表节点,主要就是起到连接的作用,整个抽象语法树的根节点也是这个类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (ast->kind == ZEND_AST_FUNC_DECL) { CG(zend_lineno) = ast->lineno; zend_compile_func_decl(NULL , ast, 1 ); CG(zend_lineno) = ((zend_ast_decl *) ast)->end_lineno; } else if (ast->kind == ZEND_AST_CLASS) { CG(zend_lineno) = ast->lineno; zend_compile_class_decl(ast, 1 ); CG(zend_lineno) = ((zend_ast_decl *) ast)->end_lineno; } else { zend_compile_stmt(ast); } if (ast->kind != ZEND_AST_NAMESPACE && ast->kind != ZEND_AST_HALT_COMPILER) { zend_verify_namespace(); } ...
三种处理方式,函数定义节点,类的定义节点,其他节点。这里我们先不深究函数和类的定义节点编译,先来看其他节点的编译。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void zend_compile_stmt (zend_ast *ast) if (!ast) { return ; } CG(zend_lineno) = ast->lineno; if ((CG(compiler_options) & ZEND_COMPILE_EXTENDED_INFO) && !zend_is_unticked_stmt(ast)) { zend_do_extended_info(); } switch (ast->kind) { case ZEND_AST_STMT_LIST: zend_compile_stmt_list(ast); break ; case ZEND_AST_GLOBAL: zend_compile_global_var(ast); break ;f case ZEND_AST_STATIC: zend_compile_static_var(ast); break ; case ZEND_AST_UNSET: zend_compile_unset(ast); break ; case ZEND_AST_RETURN: zend_compile_return(ast); break ; case ZEND_AST_ECHO: zend_compile_echo(ast); ...
再根据节点类型,再进行不同的编译方法,关于switch语句里面的选择项,可以看看去语法分析中top_statement结构里面包含的类型,在这里其实一一对应的。这里有很多编译分支,不能一一讲到,这里分析一下ZEND_AST_ECHO节点的编译。
1 2 3 4 5 6 7 8 9 10 11 void zend_compile_echo (zend_ast *ast) zend_op *opline; zend_ast *expr_ast = ast->child[0 ]; znode expr_node; zend_compile_expr(&expr_node, expr_ast); opline = zend_emit_op(NULL , ZEND_ECHO, &expr_node, NULL ); opline->extended_value = 0 ; }
再分析之前,先要熟悉echo的语法结构,心里要有个大概的echo结构的分支走向。
1 2 3 4 5 6 7 T_ECHO echo_expr_list ';' { $$ = $2} echo_expr_list: echo_expr_list ',' echo_expr { $$ = zend_ast_list_add($1, $3); } | echo_expr { $$ = zend_ast_create_list(1, ZEND_AST_STMT_LIST, $1); } echo_expr: expr { $$ = zend_ast_create(ZEND_AST_ECHO, $1); } ;
比如echo 1 , 2 会在语法分析就会给它分开,分成T_ECHO 1和T_ECHO 2都在同一个ZEND_AST_STMT_LIST同一个节点下,所以在编译处理echo语法的时候,echo后面都只有一个表达式。即需要去编译这个表达式成为ZEND_ECHO 的第一个操作数。这里需要说一下,znode 这个类型并不是opline里面定义操作数会用到的类型,只是在编译阶段会用到,最后被会转换到定义opline的zend_op结构中相对应操作数的字段。
再看一看编译表达式expr的过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void zend_compile_expr (znode *result, zend_ast *ast) CG(zend_lineno) = zend_ast_get_lineno(ast); switch (ast->kind) { case ZEND_AST_ZVAL: ZVAL_COPY(&result->u.constant, zend_ast_get_zval(ast)); result->op_type = IS_CONST; return ; case ZEND_AST_ZNODE: *result = *zend_ast_get_znode(ast); return ; case ZEND_AST_VAR: case ZEND_AST_DIM: case ZEND_AST_PROP: case ZEND_AST_STATIC_PROP: case ZEND_AST_CALL: case ZEND_AST_METHOD_CALL: case ZEND_AST_STATIC_CALL: zend_compile_var(result, ast, BP_VAR_R); return ; case ZEND_AST_ASSIGN: zend_compile_assign(result, ast); return ; case ZEND_AST_ASSIGN_REF: zend_compile_assign_ref(result, ast);
在通过遍历expr下的子节点最后会返回一个最终的expr,这个expr可能最终是个常量,也可能是经过复杂运算之后的临时变量。比如switch 第一个case 这里取的就是比如包含单引号包裹的字符串,整形,浮点型这些简单常量的zval_ast_zval节点,然后把常量对应的zval赋值给znode.u.constant,如何定义该操作数为常量类型。再来看一个比如expr是 $a //ZEND_AST_VAR这样php变量的编译过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void zend_compile_var (znode *result, zend_ast *ast, uint32_t type) CG(zend_lineno) = zend_ast_get_lineno(ast); switch (ast->kind) { case ZEND_AST_VAR: zend_compile_simple_var(result, ast, type, 0 ); return ; case ZEND_AST_DIM: ... } static void zend_compile_simple_var (znode *result, zend_ast *ast, uint32_t type, int delayed) if (is_this_fetch(ast)) { zend_op *opline = zend_emit_op(result, ZEND_FETCH_THIS, NULL , NULL ); if ((type == BP_VAR_R) || (type == BP_VAR_IS)) { opline->result_type = IS_TMP_VAR; result->op_type = IS_TMP_VAR; } } else if (zend_try_compile_cv(result, ast) == FAILURE) { zend_compile_simple_var_no_cv(result, ast, type, delayed); } }
is_this_fetch是用来判断是不是特殊变量this,这不是我们要走的分支,php的变量应该为CV变量。看第一个函数zend_try_compile_cv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static int zend_try_compile_cv (znode *result, zend_ast *ast) zend_ast *name_ast = ast->child[0 ]; if (name_ast->kind == ZEND_AST_ZVAL) { zval *zv = zend_ast_get_zval(name_ast); zend_string *name; if (EXPECTED(Z_TYPE_P(zv) == IS_STRING)) { name = zval_make_interned_string(zv); } else { name = zend_new_interned_string(zval_get_string_func(zv)); } if (zend_is_auto_global(name)) { return FAILURE; } result->op_type = IS_CV; result->u.op.var = lookup_cv(CG(active_op_array), name);
判断是不是ZEND_AST_ZVAL节点,然后取节点中的CV变量名,判断是不是auto_global变量,如果是直接返回。接着进入CV变量的逻辑,操作类型指定为IS_CV。前面已经介绍过了操作数的值是按偏移量来存储的。CV变量名依次储存在zend_op_array中的vars数组中,lookup_cv的作用就是遍历vars数组,并根据该CV变量名出现在vars数组中的位置,计算返回偏移量。如果改CV变量名并不在vars中,就会添加到其中。vars数组中是不存在重复的CV变量名的。列如改CV变量名出现在var[0],则其偏移值地址为(sizeof(zend_execute_data)+15)/16*16+0*16,在这里为80,前面说了本文zend_execute_data大小为72。并通过zend_execute_data->last_var 记录CV变量的个数。所以在这里CV操作数的偏移地址按照80,96,112...来递增。
关于操作数类型的编译。上面讲了CV类型操作数的编译过程,同时还有CONST字面量类型,这里需要注意的是,这里CONST常量的存储并不是指像C语言那样在编译过程把源代码中的显式常量都存储在同一个常量段里。举个例子:
1 2 <?php echo "hello" ."maple" ;
在这里有的同学会认为这里op_array->last_literal == 3, echo语句里面"hello","maple",还包括在编译过程中会自动添加的opline RETURN 1中的这个1,其实我刚开始的时候也有这样的困惑。在这里你需要先想一想CONST类型的操作数个数是在哪增长的?
1 2 3 4 5 6 #define SET_NODE(target, src) do { \ target ## _type = (src)->op_type; \ if ((src)->op_type == IS_CONST) { \ target.constant = zend_add_literal(CG(active_op_array), &(src)->u.constant); \ } ...
在SET_NODE这个宏里判断操作数类型是不是CONST类型,与此同时决定是否将其添加到op_array->literals常量数组里面,其实这里就是将编译过程的中间量 znode内容转换到zend_op里面,然后将这条zend_op 添加到 op_array->opcodes数组里面。所以在这里你可以认为在最终确定形成一条opline的时候,才会去判断操作数是不是CONST类型,并将其添加到字面量数组。在这里其实只有2条opline,并没有一条用来连接字符串的opline。
1 2 ECHO 'hellomaple' RETURN 1
在这里2个简单字符串的连接并没有再去编译一条opline,而是在编译过程直接调用相应的二进制处理函数,直接把连接好的字符串返回,和连接的字符串一样,+-*/|&^%<<>>**通过这些运算符的简单运算也是有相应的二进制处理函数。所以在这里其实是把连接之后"hellomaple"添加到了字面量数组。
还有TMP_VAR 和VAR类型操作数的编译,TMP_VAR操作数出现在比如,字符串连接,当然简单的字符串连接是没有中间变量的,比如'maple'.$a这样的情况下结果的返回值类型会被编译成TMP_VAR。TMP_VAR和VAR类型其实很容易弄混,这里其实好理解,TMP_VAR是在计算过程出现的临时变量。通常情况下带返回值的每一条opline的返回值类型都是VAR类型,返回值你可以决定用还是不用。比如函数调用的返回值类型,判断语句的返回值类型,简单的赋值语句的返回值类型都是VAR类型,VAR就是相当于隐式的php变量。在这里不用纠结所有情况下的操作数类型的判断,在具体的过程中你能判断即可。
还有关于VAR和TMP_VAR类型操作数的值和CV类型的操作数值一样都是偏移量,但是在这里前者两个类型的操作数的偏移不是地址偏移量,而是以此次出现的顺序递增作为偏移量,即0,1,2,3,4....这样的形式。下一个处理过程会把递增数值再转换成具体的内存偏移地址。聪明的你有想过为什么会这样做吗?是因为当CV变量,TMP_VAR,VAR都分配在zend_execute_data结果的末尾,有一个顺序所有CV变量在前依次分配,而后才是TMP_VAR,VAR这些变量,如果你在这一步就以具体地址偏移量作为除CV变量以外的值,这里会造成交叉。编译器不知道究竟有多少个CV变量,难道当出现一个CV变量就把已经存在的TMP_VAR,VAR这些变量依次往后移吗?这样做的效率太差,所以这一步只保存递增的数值,当初步完成编译整个抽象语法树之后,知道了到底有多少个CV变量,然后在最后一个CV变量的末尾依次分配。
在编译抽象语法树的过程中最主要的就是确定操作数和具体的处理函数。下面接着讲关于每一条opcode对应的处理函数。根据前面的目标,我们对整个指令集其实已经了解的差不多了,现在需要探究每一条指令集的解释过程即对应handler处理函数。这一过程在pass_two()中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 ZEND_API int pass_two (zend_op_array *op_array) ... if (CG(context).vars_size != op_array->last_var) { op_array->vars = (zend_string**) erealloc(op_array->vars, sizeof (zend_string*)*op_array->last_var); CG(context).vars_size = op_array->last_var; } ... if (op_array->literals) { memcpy (((char *)op_array->opcodes) + ZEND_MM_ALIGNED_SIZE_EX(sizeof (zend_op) * op_array->last, 16 ), op_array->literals, sizeof (zval) * op_array->last_literal); efree(op_array->literals); op_array->literals = (zval*)(((char *)op_array->opcodes) + ZEND_MM_ALIGNED_SIZE_EX(sizeof (zend_op) * op_array->last, 16 )); } ... op_array->fn_flags |= ZEND_ACC_DONE_PASS_TWO; ... opline = op_array->opcodes; end = opline + op_array->last; while (opline < end) { switch (opline->opcode) { case ZEND_RECV_INIT: { zval *val = CT_CONSTANT(opline->op2); if (Z_TYPE_P(val) == IS_CONSTANT_AST) { uint32_t slot = ZEND_MM_ALIGNED_SIZE_EX(op_array->cache_size, 8 ); Z_CACHE_SLOT_P(val) = slot; op_array->cache_size += sizeof (zval); } } break ; case ZEND_FAST_CALL: opline->op1.opline_num = op_array->try_catch_array[opline->op1.num].finally_op; ZEND_PASS_TWO_UPDATE_JMP_TARGET(op_array, opline, opline->op1); break ; case ZEND_BRK: case ZEND_CONT: ... if (opline->op1_type == IS_CONST) { ZEND_PASS_TWO_UPDATE_CONSTANT(op_array, opline, opline->op1); } else if (opline->op1_type & (IS_VAR|IS_TMP_VAR)) { opline->op1.var = (uint32_t )(zend_intptr_t )ZEND_CALL_VAR_NUM(NULL , op_array->last_var + opline->op1.var); }
前面我忘记说到CONST类型的操作数的值应该怎么确定,CONST类型的字面量会被储存到op_array->literals中,所以CONST类型的操作数的值为字面量数组中的下标。因为字面量的值不同于其他类型变量的值,并不是储存在zend_execute_data的结尾,在ZEND_PASS_TWO_UPDATE_CONSTANT这里两只转化方式,第一种是相对于当前opline的偏移地址:((char *)((op_array)->literals + (num)))-((char*)opline)),第二种是直接用 (opline->op).zv直接存储字面量zval变量地址。不同之处是前一种是64位系统的处理方式,而后一种是32为系统的处理方式。为什么可以用在64位系统上用相对寻址,这就需要去看看php内核里面内存的管理了。有兴趣的同学可以由此继续跟下去。
同样前面说到过的,这里用ZEND_CALL_VAR_NUM将TMP_VAR和VAR操作数的值也转换成内存地址的偏移量。接着具体看ZEND_VM_SET_OPCODE_HANDLER为opline添加handler的具体过程:
1 2 3 4 5 6 ZEND_API void ZEND_FASTCALL zend_vm_set_opcode_handler (zend_op* op) zend_uchar opcode = zend_user_opcodes[op->opcode]; ... op->handler = zend_vm_get_opcode_handler_ex(zend_spec_handlers[opcode], op); }
zend_spec_handlers是一个用来保存单个opcode对应的起始handler在zend_opcode_handler的位置和该opcode可以接受的操作数的个数如下:
1 2 3 4 5 6 7 8 static const uint32_t specs[] = { 0 , 1 | SPEC_RULE_OP1 | SPEC_RULE_OP2, 26 | SPEC_RULE_OP1 | SPEC_RULE_OP2, 51 | SPEC_RULE_OP1 | SPEC_RULE_OP2 | SPEC_RULE_COMMUTATIVE, 76 | SPEC_RULE_OP1 | SPEC_RULE_OP2, 101 | SPEC_RULE_OP1 | SPEC_RULE_OP2, ...
拿到可以接受操作数的个数和opcode对应的其实handler位置,计算出实际处理handler。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static const void * ZEND_FASTCALL zend_vm_get_opcode_handler_ex (uint32_t spec, const zend_op* op) static const int zend_vm_decode[] = { _UNUSED_CODE, _CONST_CODE, _TMP_CODE, _UNUSED_CODE, _VAR_CODE, _UNUSED_CODE, _UNUSED_CODE, _UNUSED_CODE, _CV_CODE }; uint32_t offset = 0 ; if (spec & SPEC_RULE_OP1) offset = offset * 5 + zend_vm_decode[op->op1_type]; if (spec & SPEC_RULE_OP2) offset = offset * 5 + zend_vm_decode[op->op2_type];
一个opcode对应的handler种类和它可以接受的操作数有关。操作数类型一共5种如上,最多一个opcode可能有两个操作数,每个操作数最多有5种类型,就出现25种不一样的形式的op1和op2 的对应关系。上述就是根据对应关系计算到handler偏移的方法,首先得根据操作数类型做一个映射把0->3, 1->0, 2->1, 4->2, 8->4。然后再根据操作数的个数,类型计算出实际处理函数的偏移量。
1 2 ... return zend_opcode_handlers[(spec & SPEC_START_MASK) + offset];
zend_opcode_handlers这个数组保存的并不是处理函数,而是标签。由此引出对应的handler的生成和调度问题。
0x05 Handler 的生成和调度
仔细想一想大概存在200种 不同类型的opcode,如果两个操作数的对应关系也按25算。那么一共应该有5000个handler。实际上没那多,但也是极其庞大的handler处理结构。ZendVM里面对于handler的处理全部定义在zend_vm_execute.h 中,这个文件其实是自动生成的,通过同级目录下的zend_vm_gen.php生成。庞大的handler分支,从生成到调度,这两个过程是分不开的。一种生成方法对应一种调度方法。生成handler的过程基本都一样,生成handler可以为内联,也可以以函数的形式来调用。为什么需要根据操作数类型把一个处理函数分成一个个只能接受指定类型的操作数的handler呢?为什么不直接写一个handler然后在里面判断操作数的类型不就行了?如果只通过一个opcode对应一个handler,那么必然要在这个handler里面对操作数类型进行判断。必然存在大量的if else这样的判断语句,判断语句本质上对应着地址的跳转,根据操作数类型就需要做大量的判断,可能就需要24次,这里就提到一个概念叫分支预测,虽然我们可以在写ifesle判断语句的时候,可以把经常出现的对应关系往前写,提高命中率,但是还是无法准确的预知操作数类型的对应关系。所以把一个处理函数分成多个处理函数,把这些处理函数的标志放在一张表里面,通过映射直接获取单个处理函数,相对于一次跳转到对应的处理函数上。在php_vm_gen.php生成使用调度方法一共有4种:
CALL类型的调度方法是把单个handler封装成函数,进行调用:
1 2 3 4 5 6 7 8 9 10 11 12 ZEND_API void execute_ex (zend_execute_data *ex) LOAD_OPLINE(); ZEND_VM_LOOP_INTERRUPT_CHECK(); while (1 ) { int ret ; ret = ((opcode_handler_t )OPLINE->handler)(ZEND_OPCODE_HANDLER_ARGS_PASSTHRU); } }
这种情况下handler指向的是处理函数,这个处理的函数作用包括具体的处理过程和处理完成之后让当前的opline指向下一条。在这里说一下当前的execute_data 中opline的指向,在编译的时候进行了优化,将指定一个全局的寄存器变量去保存当前opline的地址,同样当前的execute_data也会用一个寄存器变量来保存。在不同的架构上可能使用的寄存器不同。
1 2 3 4 5 6 # elif defined(__GNUC__) && ZEND_GCC_VERSION >= 4008 && defined(__x86_64__) # define ZEND_VM_FP_GLOBAL_REG "%r14" # define ZEND_VM_IP_GLOBAL_REG "%r15" register zend_execute_data* volatile execute_data __asm__(ZEND_VM_FP_GLOBAL_REG);register const zend_op* volatile opline __asm__(ZEND_VM_IP_GLOBAL_REG);
本文上用r14来保存execute_data,用r15来保存当前的opline。所以在进行gdb调试的时候你并不能直接打印这两个值,你需要去引用一下这个两个寄存器上相对应的变量的地址。当使用全局的寄存器变量来保存execute_data的时候,在调用相应处理函数的时候,就不需要再传递。具体看ZEND_OPCODE_HANDLER_ARGS_PASSTHRU这个宏定义。在Call调用下可能存在调用handler处理函数可能不会立即返回,而是继续在该handler里面调用下一条opline的处理函数。
SWITCH 是最容易生成的一种调度方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ZEND_API void execute_ex (zend_execute_data *ex) LOAD_OPLINE(); ZEND_VM_LOOP_INTERRUPT_CHECK(); while (1 ) { zend_vm_continue: dispatch_handler = OPLINE->handler; zend_vm_dispatch: switch ((int )(uintptr_t )dispatch_handler){ case 0 : ZEND_VM_NEXT_OPCODE(); case 1 : ... } } }
处理过程内嵌在每一个case语句里面,opline中handler保存是case的节点信息,生成这种调用方式非常简单,只需要一个顺序的映射表就行。但是这里又用写了一次switch,switch语句的效率和多个分支的if语句效率基本是相当的,不利于分支预测,每次的switch都可能跳转到任意一个case节点上,而且至少都有上千的case的分支。
GOTO相当于把Call里面的handler都写成了内联的形式,且handler之间的切换用goto来完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ZEND_API void execute_ex (zend_execute_data *ex) LOAD_OPLINE(); ZEND_VM_LOOP_INTERRUPT_CHECK(); while (1 ) { goto *(void **)(OPLINE->handler); {$spec_name}_LABEL: ZEND_VM_GUARD($spec_name); { } {$spec_name}_LABEL: ZEND_VM_GUARD($spec_name); { } ... } }
标签的地址是可以这样void *ptr = &&label; goto *ptr;用变量来表示。这样可以定义一个标签地址的数组作为映射表,opline->handler保存相应标签地址。在这里也不存在if这样的判断语句,从第一个goto开始到handler处理完成再进行goto,执行每一个goto位置都是不一样的,所以这里可以根据每一个goto进行单独的分支预测,可以把每次跳转范围减少到一个比较小的范围,提高了预测的精度。
HYBRID是7.2版本才出来的一种优化后的混合调用方式,是CALL和GOTO的结合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 ZEND_API void execute_ex (zend_execute_data *ex) LOAD_OPLINE(); ZEND_VM_LOOP_INTERRUPT_CHECK(); while (1 ) { HYBRID_SWITCH() { HYBRID_CASE(ZEND_JMP_SPEC): VM_TRACE(ZEND_JMP_SPEC) ZEND_JMP_SPEC_HANDLER(ZEND_OPCODE_HANDLER_ARGS_PASSTHRU); HYBRID_BREAK(); HYBRID_CASE(ZEND_DO_ICALL_SPEC_RETVAL_UNUSED): VM_TRACE(ZEND_DO_ICALL_SPEC_RETVAL_UNUSED) ZEND_DO_ICALL_SPEC_RETVAL_UNUSED_HANDLER(ZEND_OPCODE_HANDLER_ARGS_PASSTHRU); HYBRID_BREAK(); ... HYBRID_CASE(ZEND_RETURN_SPEC_CONST): VM_TRACE(ZEND_RETURN_SPEC_CONST) { USE_OPLINE zval *retval_ptr; zval *return_value; zend_free_op free_op1; retval_ptr = RT_CONSTANT(opline, opline->op1); return_value = EX(return_value); if (IS_CONST == IS_CV && UNEXPECTED(Z_TYPE_INFO_P(retval_ptr) == IS_UNDEF)) { .... goto zend_leave_helper_SPEC_LABEL; } } }
你看到的是在分支的选择上用的goto,handler的表现形式是有函数调用也有内联,如果把所有的函数调用都换成内联的形式,其实就是goto的调用方法。在HYBRID这个模式里面如果你看到handler定义为ZEND_VM_HOT,其实就是内联函数体。
以上四种生成不同VM模式,既然是用zend_vm_gen.php生成的VM,如果我们想要添加新的handler就需要去zend_vm_def.h 定义新handler,现在来看一看定义新handler的格式,如下为echo的handler定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ZEND_VM_HANDLER(40 , ZEND_ECHO, CONST|TMPVAR|CV, ANY) { USE_OPLINE zend_free_op free_op1; zval *z; SAVE_OPLINE(); z = GET_OP1_ZVAL_PTR_UNDEF(BP_VAR_R); if (Z_TYPE_P(z) == IS_STRING) { zend_string *str = Z_STR_P(z); if (ZSTR_LEN(str) != 0 ) { zend_write(ZSTR_VAL(str), ZSTR_LEN(str)); } } else { zend_string *str = zval_get_string_func(z); if (ZSTR_LEN(str) != 0 ) { zend_write(ZSTR_VAL(str), ZSTR_LEN(str)); } else if (OP1_TYPE == IS_CV && UNEXPECTED(Z_TYPE_P(z) == IS_UNDEF)) { GET_OP1_UNDEF_CV(z, BP_VAR_R); } zend_string_release_ex(str, 0 ); } FREE_OP1(); ZEND_VM_NEXT_OPCODE_CHECK_EXCEPTION(); }
标志的handler定义需要使用ZEND_VM_HANDLER作为起始,括号里面的参数分别为,opcode整数值,opcode常量,操作数1类型,操作数2类型,可能还存在一个参数为分割的flag参数。有时候会在操作数类型里面看到其他不一样的操作数类型,比如NEXT,ANY,THIS等等,其实这些并不是操作数类型,相当于flag额外的属性,并不参加操作数1和操作数2的笛卡尔集的对应关系。
handler定义里面还有类似GET_OP1_ZVAL_PTR_UNDEF这样的取值标记,在这里我们不用考虑不同操作数的取值方法,zend_vm_gen.php在内部做了映射,会根据不同的操作数类型替换这样的标记,如下:
1 2 3 4 5 6 7 8 9 10 $op1_get_zval_ptr_undef = array ( "ANY" => "get_zval_ptr_undef(opline->op1_type, opline->op1, &free_op1, \\1)" , "TMP" => "_get_zval_ptr_tmp(opline->op1.var, &free_op1 EXECUTE_DATA_CC)" , "VAR" => "_get_zval_ptr_var(opline->op1.var, &free_op1 EXECUTE_DATA_CC)" , "CONST" => "RT_CONSTANT(opline, opline->op1)" , "UNUSED" => "NULL" , "CV" => "EX_VAR(opline->op1.var)" , "TMPVAR" => "_get_zval_ptr_var(opline->op1.var, &free_op1 EXECUTE_DATA_CC)" , "TMPVARCV" => "EX_VAR(opline->op1.var)" , );
如果想看更多定义的替换规则,可以去看zend_vm_gen.php文件里面靠前的位置。可能有时候会看见类型下面的判断语句
1 2 3 4 5 6 7 8 9 10 11 if (IS_CV == IS_VAR && UNEXPECTED(Z_ISERROR_P(variable_ptr))) { if (UNEXPECTED(0 )) { ZVAL_NULL(EX_VAR(opline->result.var)); } } else { value = zend_assign_to_variable(variable_ptr, value, IS_CONST); if (UNEXPECTED(0 )) { ZVAL_COPY(EX_VAR(opline->result.var), value); } }
IS_CV==IS_VAR这种奇怪的条件,这是因为zend_vm_gen.php在生成handler的时候是直接替换的操作数类型。 if (OP1_TYPE == IS_VAR && UNEXPECTED(Z_ISERROR_P(variable_ptr))) {,就造成了这种情况,是无用的判断条件,在编译的时候编译器会自行优化掉这些判断条件,所以并不造成影响。
VM的生成到调用,需要掌握的是怎样是去定义或者修改正确的handler,让zend_vm_gen.php能正常的处理,指定相应的调度方式,最终生成zend_vm_execute.h。这过程需要自己去实践才能明白一条可用的handler是怎样生成的。
终于handler的分配到这里也结束了,在pass_two结束遍历所有的oplines,前面整个编译过程就结束了,接下来就是进入执行过程。整个VM的执行过程都是zend_vm_execute.h生成的,通过填充zend_vm_execute.skl里面相关函数,生成完整的zend_execute(),execute_ex()。
0x06 执行过程
进入zend_execute
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ZEND_API void zend_execute (zend_op_array *op_array, zval *return_value) zend_execute_data *execute_data; if (EG(exception) != NULL ) { return ; } execute_data = zend_vm_stack_push_call_frame(ZEND_CALL_TOP_CODE | ZEND_CALL_HAS_SYMBOL_TABLE, (zend_function*)op_array, 0 , zend_get_called_scope(EG(current_execute_data)), zend_get_this_object(EG(current_execute_data))); if (EG(current_execute_data)) { execute_data->symbol_table = zend_rebuild_symbol_table(); } else { execute_data->symbol_table = &EG(symbol_table); } EX(prev_execute_data) = EG(current_execute_data); i_init_code_execute_data(execute_data, op_array, return_value); zend_execute_ex(execute_data); zend_vm_stack_free_call_frame(execute_data); }
execute_data相当于处理当前op_array的context上下文,当前context里面的CV变量,临时变量均分配在execute_data结尾。
zend_execute_ex = execute_ex;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ZEND_API void execute_ex (zend_execute_data *ex) DCL_OPLINE #ifdef ZEND_VM_IP_GLOBAL_REG const zend_op *orig_opline = opline; #endif #ifdef ZEND_VM_FP_GLOBAL_REG zend_execute_data *orig_execute_data = execute_data; execute_data = ex; #else zend_execute_data *execute_data = ex; #endif LOAD_OPLINE(); ZEND_VM_LOOP_INTERRUPT_CHECK(); while (1 ){ }
这里具体的调用handler的过程上面已经将的差不多了,这里看看返回的过程,返回的标志是RETURN,相应的handler会根据操作数1的不同类型将返回值zval赋值给EX(return_value),最后会跳转到下面的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 zend_leave_helper_SPEC_LABEL: zend_execute_data *old_execute_data; uint32_t call_info = EX_CALL_INFO(); if (EXPECTED((call_info & (ZEND_CALL_CODE|ZEND_CALL_TOP|ZEND_CALL_HAS_SYMBOL_TABLE|ZEND_CALL_FREE_EXTRA_ARGS|ZEND_CALL_ALLOCATED)) == 0 )) { ... }else if (EXPECTED((call_info & (ZEND_CALL_CODE|ZEND_CALL_TOP)) == 0 )) { ... }else if (EXPECTED((call_info & ZEND_CALL_TOP) == 0 )) { .. }else { if (EXPECTED((call_info & ZEND_CALL_CODE) == 0 )) { ... }else { zend_array *symbol_table = EX(symbol_table); zend_detach_symbol_table(execute_data); old_execute_data = EX(prev_execute_data); while (old_execute_data) { if (old_execute_data->func && (ZEND_CALL_INFO(old_execute_data) & ZEND_CALL_HAS_SYMBOL_TABLE)) { if (old_execute_data->symbol_table == symbol_table) { zend_attach_symbol_table(old_execute_data); } break ; } old_execute_data = old_execute_data->prev_execute_data; } EG(current_execute_data) = EX(prev_execute_data); ZEND_VM_RETURN(); }
这里通过判断调用者的信息决定如何返回。调用者信息有下面几种,除了开始"main" op_array的execute_data调用,其他几种都是涉及到切换execute_data,切换的时候会创建新的execute_data。最后分支是main execute_data的返回,其中zend_detach_symbol_table是清理execute_data末尾的CV和临时变量。
1 2 3 4 5 6 typedef enum _zend_call_kind { ZEND_CALL_NESTED_FUNCTION, ZEND_CALL_NESTED_CODE, ZEND_CALL_TOP_FUNCTION, ZEND_CALL_TOP_CODE } zend_call_kind;
最后execute_ex返回,再调用zend_vm_stack_free_call_frame()释放掉execute_data。这里不是真正的释放,而是把相应的内存归还给Zend 的内存池,避免频繁的申请和释放。有兴趣的同学可以去看看Zend的内存管理。
到这里ZendVM编译和执行过程也就差不多介绍个大概,其实还有很多细节值得推敲。比如opcode缓存,opcode 的优化等等,关于opcode缓存和php7.4 alpha1的新特性FFI应该是我下一篇文章,在写本文的时候,恰巧也是php7.4 alpha1 release的时候,只感觉php变得很快,越来越不局限于Web的专属语言了。
0x7 牛刀小试
说了这么多,你们可能也想试一试如何去增加一个新的php语法,这里我将通过一个简单的例子描述这一过程。其实通过前面基础介绍从 词法扫描->语法分析->抽象语法树->oplines->zend_execute 这已基本过程也应该了解了。现在我们添加一个 关于in的语法 ,在JavaScript里面 in 作为运算符用来判断指定的属性是否在指定的对象或其原型链中,返回值为bool类型,同样在python里面也有in运算符,使用于字符串和字典运算。字典类似于php里面的数组,js 和 python 的in运算符应用于string in ['b','a','c']这样运算的时候,js判断是数组的key值 ,而python关注的value值,类似于php的in_array。这里我们添加一个比较简单的语法用in来代替strpos。
最终的效果应该是
1 2 3 var_dump('maple' in 'hello , maple'); //int(8) var_dump(1 in '11111'); //bool(false) var_dump('' in 'maple'); //bool(false)
这里in两边表达式不进行弱类型转化,如strpos一样,应该都为字符串类型。一步一步来。
首先需要在词法扫描的时候碰到"in" 返回 'T_IN';
T_IN 作为运算符和+-*/%这些运算符意义相同,应该出现在表达式里面。
先完成第一步re2c扫描的时候,遇到"in",返回token,需要在zend_language_scanner.l中lex_scan()中添加相应的正则匹配规则。
1 2 3 <ST_IN_SCRIPTING>"in" { RETURN_TOKEN(T_IN); }
这里有同学可能会问应该放在什么位置,在这里其实放在任意位置都行,只要在/*!re2c内就行,因为这里不存在冲突,存在一个include规则,但是re2c在处理匹配的相同字符串的规则的时候,是优先取长的。所以include和in并不冲突。
然后去zend_language_parser.y去定义一下T_IN相关语法。
1 2 3 4 5 6 %token T_IN "in (T_IN)" expr: ... |expr T_IN expr { $$ = zend_ast_create_binary_op(ZEND_IN, $1 , $3 ); } ... ;
引入token和定义相关语法,其实还需要做一些事情,否则bison还是无法处理。比如
这种情况下究竟是 ('stra' in 'strb' ) && 1 还是'stra' in ('strb' && 1),会导致bison无法处理。所以这里我们还需要定义in的优先级。再比如下面
1 'stra' in 'strb' in 'strc'
究竟是('stra' in 'strb') in 'strc'还是'stra' in ('strb' in 'strc')呢?这里需要定义结合性。结核性好考虑%left 即可。
再考虑优先级应该放在什么位置
1 2 3 4 'stra' in 'strb' && 1 ('stra' in 'strb' ) && 1 'stra' in 'strb' .'strc' 'stra' in ('strb' .'strc' )
&& 和+, -, .之间的token如下
1 2 3 4 5 6 7 8 %left T_BOOLEAN_AND %left '|' %left '^' %left '&' %nonassoc T_IS_EQUAL T_IS_NOT_EQUAL T_IS_IDENTICAL T_IS_NOT_IDENTICAL T_SPACESHIP %nonassoc '<' T_IS_SMALLER_OR_EQUAL '>' T_IS_GREATER_OR_EQUAL %left T_SL T_SR %left '+' '-' '.'
应该在大于号小于号 之后,而又应该在位运算符之前之后都行。我放在了位运算后面,这里in两边的表达式应该为字符串类型,不适用于位运算。所以这里插入位置如下
1 2 3 %left T_SL T_SR %left T_IN %left '+' '-' '.'
便完成了语法分析的修改。接着关于in语法节点的建立。我们可以看一下其他简单运算符的建立的过程。
1 2 3 4 5 6 7 8 9 | expr '|' expr { $$ = zend_ast_create_binary_op(ZEND_BW_OR, $1 , $3 ); } | expr '&' expr { $$ = zend_ast_create_binary_op(ZEND_BW_AND, $1 , $3 ); } | expr '^' expr { $$ = zend_ast_create_binary_op(ZEND_BW_XOR, $1 , $3 ); } | expr '.' expr { $$ = zend_ast_create_binary_op(ZEND_CONCAT, $1 , $3 ); } | expr '+' expr { $$ = zend_ast_create_binary_op(ZEND_ADD, $1 , $3 ); } | expr '-' expr { $$ = zend_ast_create_binary_op(ZEND_SUB, $1 , $3 ); } | expr '*' expr { $$ = zend_ast_create_binary_op(ZEND_MUL, $1 , $3 ); } | expr T_POW expr { $$ = zend_ast_create_binary_op(ZEND_POW, $1 , $3 ); }
都通过zend_ast_create_binary_op来建立节点,其实建立是一个ZEND_AST_BINARY_OP类型的节点,然后将该节点attr设置为相应的opcode,我们再去看一下关于ZEND_AST_BINARY_OP节点编译成opcode的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void zend_compile_expr (znode *result, zend_ast *ast) ... switch (ast->kind) { case ZEND_AST_BINARY_OP: zend_compile_binary_op(result, ast); ... } } void zend_compile_binary_op (znode *result, zend_ast *ast) zend_ast *left_ast = ast->child[0 ]; zend_ast *right_ast = ast->child[1 ]; uint32_t opcode = ast->attr; znode left_node, right_node; zend_compile_expr(&left_node, left_ast); zend_compile_expr(&right_node, right_ast); if (left_node.op_type == IS_CONST && right_node.op_type == IS_CONST) { if (zend_try_ct_eval_binary_op(&result->u.constant, opcode, &left_node.u.constant, &right_node.u.constant) ) { result->op_type = IS_CONST; zval_ptr_dtor(&left_node.u.constant); zval_ptr_dtor(&right_node.u.constant); return ; } }
这里我们先把如果 in 两边是字面量的处理过程写出来,例如'aaaaaaa' in 'bbbbbbbb',所以这里我们需要去添加相应的内置函数来处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static inline zend_bool zend_try_ct_eval_binary_op (zval *result, uint32_t opcode, zval *op1, zval *op2) binary_op_type fn = get_binary_op(opcode); ... } ZEND_API binary_op_type get_binary_op (int opcode) switch (opcode) { case ZEND_ADD: case ZEND_ASSIGN_ADD: return (binary_op_type) add_function; case ZEND_SUB: case ZEND_ASSIGN_SUB: return (binary_op_type) sub_function; case ZEND_MUL: case ZEND_ASSIGN_MUL: ... }
这里我们需要添加 ZEND_IN的case分支如下
1 2 3 4 5 6 ... case ZEND_IN: return (binary_op_type) in_function; default : return (binary_op_type) NULL ; ...
接着去定义in_function,在zend_operators.c中,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ZEND_API int ZEND_FASTCALL in_function (zval *result, zval *op1, zval *op2) const char *found = NULL ; if (Z_TYPE_P(op2) == IS_STRING){ if (!Z_STRLEN_P(op2)) { ZVAL_FALSE(result); }else { if (Z_TYPE_P(op1) == IS_STRING ){ if (!Z_STRLEN_P(op1)){ ZVAL_FALSE(result); }else { found = (char *)zend_memnstr(Z_STRVAL_P(op2), Z_STRVAL_P(op1), Z_STRLEN_P(op1), Z_STRVAL_P(op2) + Z_STRLEN_P(op2)); } }else { ZVAL_FALSE(result); } } }else { ZVAL_FALSE(result); } if (found){ ZVAL_LONG(result,found-Z_STRVAL_P(op2)); }else { ZVAL_FALSE(result); } retuSrn SUCCES; }
改函数实现了strpos不带offset的功能。记得还要去zend_vm_opcodes.h去定义一下新添加的ZEND_IN.使用bison重新预处理一下zend_language_parser.y,同样也需要使用re2c重新处理一下zend_language_scanner.l。重新编译整个php。你就会看到预期in左右两边字面量的新语法。接着还有'a' in $a,'a' in foo(),就需要使用zend_vm_gen.php 去生成相对应的handler。有兴趣的同学可以去接着深入,这里的东西再怎么陈述,你终究会有一些不懂的地方。
0x08 写在最后
终于php的编译和执行到此就结束了,从前到后其实就是在不断的重新编译php,然后配合gdb。很多人觉得庞大的代码很难入手,其实把大致逻辑梳理一遍,再针对性的看,也不是很难下手,原希望这篇文章作为一篇基础的入门级文章送给那些渴求一探php内部奥秘的朋友,不在某一个细节上过于深究,留下可探究的点,供大家参考。如果大家能从此篇学到一些东西,那我这一段时间就没用白费 :)。同时送给大家一段我看见挺正确的话:
我觉得韩天峰有句话说的很对,技术栈上,PHP 只是 C 的一个开发效率提升的补充,资深的高级 PHP 程序员,很多时候都是很好的 C 程序员(参考鸟哥),C 对于 PHP 不是后门,是基石。PHP 极早期很多函数就是对 C 的一些简单封装,你可以看下 PHP4 时代遗留下来的东西,很多有很重的 C 痕迹,PHP5 拥抱 oop 不是和 Java 学,而是跟着语言发展潮流走,拥抱开发方式的发展和变化,但是发展到现在,有人觉得弄出 laravel 那种花式封装的就是高级 PHP 程序员了,其实离真的高级资深 PHP 程序员还远着十万八千里。
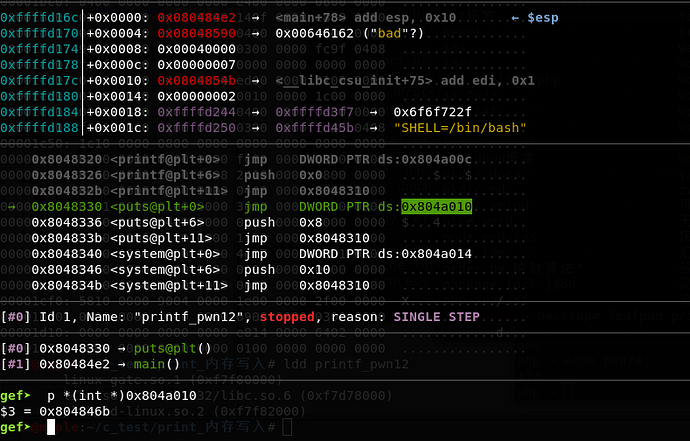
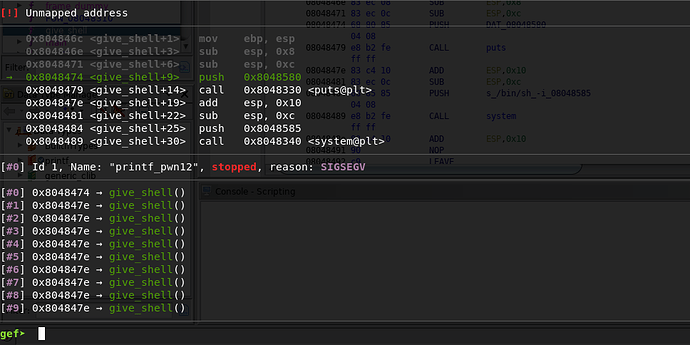
 give_shell应该相当于一个one_gadget,所以这里的基本第一思路是让
give_shell应该相当于一个one_gadget,所以这里的基本第一思路是让