case 6: F1 -> F2 -> F3 -> ... -> Fn -> expected_freelist
case 6讨论是一个非常实际的问题,我们期望的内存布局往往需要保持某个特定的PHP脚本执行的地方。然而,利用PHP处理HTTP请求构造的内存布置,极有可能被后续的PHP引擎本身或者PHP脚本运行所破坏。在part2 中,作者也提到了这一点。因此,我们需要去规避在这些过程里面的内存操作对我们的影响。有一个很简单的优化规避方法是尽可能使用目标应用的比较少的小内存类型,比如使用一些较大的小内存,但是我们还是从根本上解决这个问题。另外一个非常自然的想法就是在我们构造的freelist之前去填充一些可用的slots,让这些去满足额外的内存操作。但是,要填充多少slots,我们并不知道,这跟目标环境有关系。因此这里可能存在一个多次尝试的过程。一般地,我们填充过程如下:
前面我们提到了_to参数的大小是接近0x800,并且是可以对齐到0x800,意味着在mb_convert_encoding这里会使用一个0x800-slot。这会导致什么问题呢? 在P0处理完之后,直到P1处理开始,freelist会变成 F -> A -> D -> B -> C。没错,多了一个0x800,导致后续利用出问题。这是作者文章中没有提到的东西,因此这是一个异常0x800-slot申请。
在刚刚过去的defcon quals 2024上出现了Mojo[1]写的应用,看见了小伙伴对它的吐槽,我也很好奇它到底是怎样的一个语言,决定深入探索一下。Mojo的主推者Chris Lattner同时是LLVM和Swift的创始人,我想这样优秀的编程语言领域工程师,品控一定不会太差。很早之前就听闻过Mojo,但是一直没有尝试过去了解它,对它的印象仅仅是来源于它本身的一个宣传 "专为AI设计的语言,兼容Python,并且要比Python快xxx倍"。那么我觉得它的定位,或者说试用人群,应当是那些以Python为主,并且想要写出高质量的代码的AI工程师。
#https://github.com/modularml/mojo/blob/main/stdlib/src/collections/list.mojo#L90 struct List[T: CollectionElement](CollectionElement, Sized, Boolable): """The `List` type is a dynamically-allocated list. It supports pushing and popping from the back resizing the underlying storage as needed. When it is deallocated, it frees its memory. Parameters: T: The type of the elements. """ var data: UnsafePointer[T] """The underlying storage for the list.""" var size: Int """The number of elements in the list.""" var capacity: Int ...
I first learned about this from Laruence (鸟哥) who is a core member of PHP development group. His blog was a place I often visited when I was studying the PHP internals in the early days. In 2020, Laruence posted an article titled "Understanding the HashTable of PHP 7 Internals in Depth" [2]. At the end of the article, he mentioned an issue:
In implementing zend_array to replace HashTable, we encountered many problems, most of which have been solved. However, one problem remains unresolved. Because arData is continuously allocated now, when the array grows to the point of needing to be resized, we can only realloc memory. However, the system does not guarantee that the address will not change after you realloc. So, it is possible that:
In the example above, $array is a global array, then it is referenced in the function crash, in the += opcode handler, zend vm will first get the content of array[0], then +$var. But $var is an undefined variable, so at this time, an undefined variable notice will be triggered. Meanwhile, we set an error_handler, in which we add an element to this array. Because arrays in PHP are pre-allocated with 2^n space, at this point, the array is full and needs to be resized, so realloc occurs. After returning from the error_handler, the memory pointed to by array[0] may have changed, resulting in memory read and write errors, or even segfaults. Interested students can try running this example with valgrind to see.
But the trigger conditions for this problem are quite numerous, fixing it would require additional modifications to the data structure, or splitting the add_assign could impact performance. Additionally, in most cases, due to the existence of the array's pre-allocation strategy and the fact that most multi-opcode handler read-write operations are basically close, this problem is actually difficult to be triggered by actual code. So, this problem has been hovering.
Even today, this problem still hovers. For the most of PHP developers, this may indeed not be a significant issue, but for an experienced security researcher, there may be a serious security issue hidden here. Because it is one of the few issues I have seen in the PHP VM rather than in various PHP native libraries. Once exploitable, the impact will be significant. So, this problem has always been on my mind, and it has been in my PHP-exploit repo as crash.php [3] for 4 years. Especially, as long as you run it with PHP 7 or 8, it will cause a segmentfault, and I don't know if anyone has tried it.
1.2 Resistance to Fixing the Problem
Laruence's explanation is very clear, here I try to use more popular pseudo-code to further help readers who are not familiar with the PHP internals understand what PHP VM is doing at line 11:
1 2 3 4 5 6 7 8 9
// array = [0, 1, 2, 3, 4, 5, 6, 7] arr_base = get_base_addr_of(array) elem_addr = get_addr_by_index(array_base, index) elem = get_elem_from_addr(elem_addr) // elem is ok check_var(var) // is elem ok? res = add(elem, var) assign_var_to_elem(elem, res)
Here are a few things done here:
First, we get the starting address of the memory area where array stores elements.
Get the memory address of the specific element specified by index.
Read the element from elem_addr to elem.
Check the legality of var. More specifically, when var is an explicitly defined variable in PHP code (i.e., $a), check if it has been defined. If var is an undefined PHP variable, then the VM initializes its value to null. Because the VM cannot directly expose undefined to user code.
Perform arithmetic addition on elem and var to get the result res.
Finally, assign res to elem.
The problem occurs at line 6, where check_var(var) may have side effects, thus clobbering the world. I learned this term from JavaScriptCore (the WebKit's JavaScript engine), where the appearance of side effects may cause previous computation results unavailable. In this case, we cannot directly use these computation results. Is elem still correctly pointing to the target element to be written after line 6? We cannot be sure after line 6, because the memory address it points to may have been released, and the correct target element position may have been moved to another memory.
The above is actually a rough explanation of the PHP opcode ZEND_ASSIGN_DIM_OP, and you can find the complete explanation in [4]. So why hasn't this problem been fixed? Good question. Let's start with a few intuitively feasible simple fixes to explain where the resistance to fixing lies. Here, I use array->arData to represent the memory address pointing to the first element, and the rest of the elements of array are sequentially located after it.
Simple Fix 1: Check if elem is still located at the relative position of array->arData after line 6
This can only ensure that array->arData has not changed, but how do you guarantee no ABA problem? For example, the storage element area of array is released, then occupied by other memory structures, then released again, and then arranged as the layout of the original storage element area of array (another array2 with the same structure occupies this area).
Simple Fix 2: Move check_var to the very beginning
So you consider the following code snippet:
1
$array['a']['b'] = $var;
This code will be translated into intermediate code similar to the following:
Here we consider ZEND_ASSIGN_DIM without binary operations. The above code is equivalent to:
1 2
V2 =& $array['a']; V2['b'] = $var;
Where V2 points to the position of the index 'a' element in $array, so I use =& here to emphasize that V2 is not $array['a']. So, the problem arises, if the side effects in line 2 cause $array to be resized, then the position pointed to by this V2 is incorrect.
This problem is destined not to be simply fixed.
1.3 unset and reassign
You can try replacing the previous resize operation with unset or reassign, as follows:
function crash() { global $array; $array[0] += $var; //undefined notice }
crash();
There are some differences between the two cases:
unset($array) simply "cleans up" $array in the current function scope and does not affect the global variable $array, so there is no problem here.
$array = 2 will affect all places that reference it, so the same problem as resizing occurs here.
Interestingly, the official has already noticed such problems, for example, it checks the side effects caused by undefined index (i.e., $arr[$undef_var] = 1). But no check is made on the value to be written.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
static zend_never_inline zend_uchar slow_index_convert(HashTable *ht, const zval *dim, zend_value *value EXECUTE_DATA_DC) { switch (Z_TYPE_P(dim)) { case IS_UNDEF: { /* The array may be destroyed while throwing the notice. * Temporarily increase the refcount to detect this situation. */ if (!(GC_FLAGS(ht) & IS_ARRAY_IMMUTABLE)) { GC_ADDREF(ht); } ZVAL_UNDEFINED_OP2(); if (!(GC_FLAGS(ht) & IS_ARRAY_IMMUTABLE) && !GC_DELREF(ht)) { zend_array_destroy(ht); return IS_NULL; } // ...
Here it first increases the reference count of ht (HashTable is an alias of zend_array) to hold this array. Then, after the error handling function returns, it subtracts the previously added reference count. If the reference count has not changed, it means that the array has not been released.
1.4 Possible fixes
Changing ZEND_ASSIGN_DIM or ZEND_ASSIGN_DIM_OP (including all array fetch operations) to support multi-index is what I think is the most direct approach. For example, the previous $array['a']['b'] = $var; will be translated to:
And before this, all indexes and expressions corresponding to the value to be written are calculated. Note that this will not change the current PHP evaluation order. Consider the following code:
$a = []; set_error_handler(function($err, $msg){echo$msg."\n";}); echo$a[func1()][func2()]; /* output at PHP 8.3.3: func1 func2 Undefined array key 1 Trying to access array offset on null */
You can check that all indexes are calculated first.
1.5 Things are Never as Simple as They Seem
Initially, I didn't intend to open an issue for this problem in the PHP repository because I assumed that the core developers of PHP were already aware of it. It first appeared in bug78598, and at that time, Nikita Popov only noticed the undefined index issue, which happened in 2019. However, I still opened an issue to remind PHP developers of the problem. Through this issue, I learned that there were still people working on it. It was only then that I realized the provided fix could only address simple cases of array assignment/fetch because I had forgotten that object assignment and fetch also had similar issues. Ilija Tovilo made two efforts:
I am very grateful to Ilija, and through our communication, I learned about the concept of delayed error. This idea is completely opposite to my previous idea. My initial idea was to throw errors as soon as possible, causing the side effects to take effect before fetching the address of the element. In contrast, delayed error is a concept where the error occurring during array assignment is deferred until after the array assignment is complete.
Delayed error handling is somewhat similar to normal exception handling, but unlike normal exceptions, delayed error handling will continue executing the next opcode that triggered it after it finishes. It's somewhat similar to algebraic effects in functional programming. There are still some issues to address in implementing delayed error handling, such as how to handle it in the current PHP JIT and which parts of PHP need this mechanism and need to be manually triggered. For more details, you can refer to the issue.
This problem is even more complex than I initially thought, and Ilija referred to it as "fundamentally hard." It will probably persist for a long time in the future...
0x02 Three Butterflies
TL;DR. If you don't want to hear the story, you can skip this section.
Four years ago, after learning about this problem, I began to explore how to exploit it. Unfortunately, I'm not very smart, and for four years I haven't come up with a solution. Over the past four years, my work has been closely integrated with PHP, and I've written about 40-50k lines of code in PHP, almost creating a whole new PHP interpreter. It's hard to imagine that this is something a security researcher would do. So I know a little bit more about PHP.
I was able to complete this article because of three butterflies. The first butterfly taught me some new methods; the second butterfly showed me a new continent; and the third butterfly led me out of trouble.
Before, I was actually trapped in a misunderstanding. My basic idea was:
array will be resized.
Then I immediately get the memory released by array, so I can create a UAF.
There's no problem here.
Here's the pseudo-code similar to ZEND_ASSIGN_DIM about ZEND_ASSIGN_DIM_OP I posted earlier:
But the problem is, assign_var_to_elem can only write a special null value to the target memory (as mentioned earlier, var will be initialized to null), and elem needs to be checked during the process. In other words, the target memory needs to have a rather strict memory layout. Secondly, influenced by the $a[0] += $var in Laruence's code, I think this null can only be written slightly ahead in this memory. That's where my misconception lies. Combining the above reasons has always prevented me from finding a suitable structure to hold this memory.
In the past, I gradually stopped paying attention to security issues in PHP, and sometimes I found some problems when writing code, but I just fixed it and no more following. It wasn't until recently when I saw the news about LockBit that I suddenly became interested and wrote "CVE-2023-3824: Lucky Off-by-one (two?)" [5]. A few days after finishing the article, I went to browse the security communities to see what everyone was researching. It was during this process that I discovered the three butterflies.
First, I found an article "Summary of WebAssembly Security Research" [6]. This article introduces how to attack Wasm engines by constructing malicious bytecode, which is quite interesting. There are similar problems in PHP opcache. I personally prefer some security research on interpreters and compilers, so I wanted to see if there was any deeper research on Wasm and searched for other articles by the author.
The First Butterfly
I found that the author had many studies on JavaScriptCore (jsc), which I hadn't encountered before, only briefly encountering V8. It seems quite interesting, so let's take a look. With the help of the article [7] and the series of articles [8], my wrote an another article "CVE-2018-4262: Apple Safari RegExp Match Type Confusion by JIT". During this process, I accumulated some knowledge about jsc. In particular, some constructions (box/unbox) in it broadened my horizons, which were quite amazing, to the point where I wanted to replicate them in PHP exploitation constructions. In jsc, there is a special structure called butterfly for storing JSObject's properties and elements, because its memory structure resembles a butterfly with wings, hence the name butterfly. The ascii graph comes from [9].
This structure is frequently used in jsc exploitation, including the box/unbox technique I mentioned earlier. This is the first butterfly.
The Second Butterfly
While reading [9], I also saw saelo's blog post "Pwning Lua through 'load'" [10]. These are the things I like to read, so let's read it. I was surprised to find that Lua actually doesn't have a bytecode verifier, and the content of the article is quite similar to the previous one attacking Wasm engines. Then I wanted to see some security research on Lua for a better understanding and found a series of security researches on LuaJIT by bigshaq [11], where I encountered the second butterfly. LuaJIT's JIT compiler translates the collected trace into IR and puts it in a structure similar to a butterfly. It looks like this:
Instructions are on one wing, and constants are on the other wing. In this brief LuaJIT journey, I accumulated some knowledge about LuaJIT, but I found that the last research on security issues was too deliberate, after all, it was a CTF problem, understandable. However, the technique of fixing the shellcode using guarded assertions in JIT code is really good.
The Last Butterfly
JIT technology in PHP 8 is heavily influenced by LuaJIT. So much so that in a blog post by bigshaq about PHP, the related exploits from LuaJIT can applied in PHP. After a big circle, I returned to PHP again and suddenly discovered that Dmitry had created a JIT Compilation Framework [11] called IR. Dmitry is the man who wrote almost all the optimizers in PHP by himself, and I deeply admire him for that. When I heard about IR, I was restless for a long time. The new JIT compiler based on IR has been merged into the master branch of PHP-src, and the annoying DynAsm is finally gone. I immediately looked at Dmitry's introduction to it [13], and finally I have a chance to not have to write a optimizer on PHP bytecode. I saw optimizations similar to Sea of Nodes in V8 TurboFan and various new optimizations that hasn't appeared in PHP. At this moment, I decided to do something for it in the future. Because the optimizers Dmitry wrote had been with me for a long time.
I remembered the IR flaw mentioned in the article, and I thought it should be over now. I started to examine it again, and my gaze returned to zend_array in PHP. Doesn't it also have a butterfly there? The ascii graph comes from [14].
PHP has two special arrays, packed arrays and mixed arrays. When I was thinking about them, this butterfly popped into my mind. It turns out that I don't need to write that null slightly ahead in memory; I can have null written to the middle of this memory. I even forgot that I could control the position of writing this null by adjusting the index. This mistake has been with me for four years. It turns out that the butterfly has always been there, on that branch I could see.
0x03 Prerequisite for PHP Internals
When I wrote content related to the PHP kernel before, I almost never included related pre-knowledge, because I didn't want to copy and paste a large amount of code, which didn't look very good. But this time, I hope more people can learn something from this article. The pre-knowledge used in this article won't be too much, so don't worry. If there are any parts you don't understand, you can email me and ask, but I can't guarantee a timely reply.
3.1 zval Structure
Variables in PHP appear in the form of zval, which is a tagged union:
struct _zval_struct { zend_value value; /* value */ union { uint32_t type_info; struct { ZEND_ENDIAN_LOHI_3( zend_uchar type; /* active type */ zend_uchar type_flags; union { uint16_t extra; /* not further specified */ } u; ) } v; } u1; union { ... } u2; };
This is very common in programming language design, such as the variable representation JSValue in JavaScriptCore. So when understanding the internals of a programming language, you need to pay attention to its variable representation. The zval.value will store the actual value of the variable, while zval.u1.type_info will store the type information of the variable.
undefined, null, false, and true can be distinguished directly by their type information;
long and double are stored directly as primitive values in zval.value.lval and zval.value.dval;
string, array, object, resource, reference, and constant_ast each have corresponding specific structures, and their addresses will be stored as pointers in zval.value.str, zval.value.arr, etc.
3.3 zend_string Structure
zend_string is used to describe the string type mentioned above. Its structure is as follows:
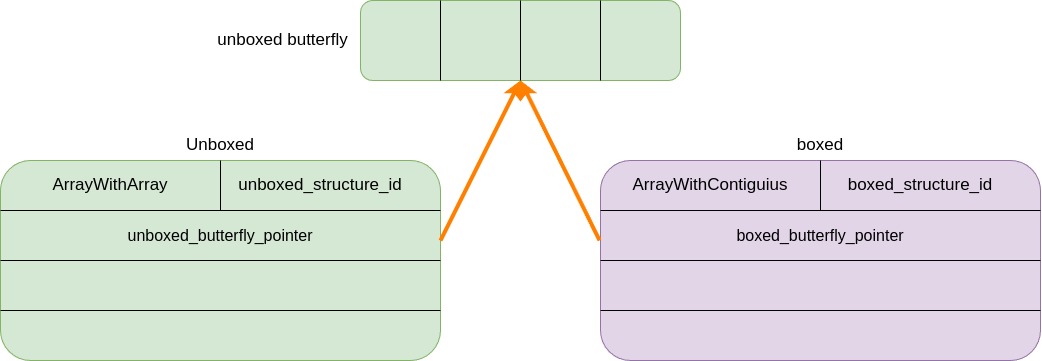
Where zend_array.arData points to the first element. Note that it does not point to the start of the allocated memory; there are two index cells (each cell size is 4 bytes) in front, both storing HT_INVALID_IDX == -1. Because in a packed array, there is no need to hash the index; we can directly retrieve the value based on the index. So what are these two invalid indices doing here? They are for future use of non-integer indices in array fetches. I was previously stuck on packed arrays.
The elements in PHP arrays are stored sequentially in memory. To resolve hash collisions, PHP links elements with the same hash into a linked list. So, to find the correct element in a mixed array, the following steps are taken:
Hash the index to get the value h.
Calculate where it falls in the index table based on h | ht->nTableMask, where the index table is the area in the first element. Each index cell in the index table stores the head node of the linked list where the target element is located and the offset of ht->arData.
Start traversing the linked list from ht->arData[h | ht->nTableMask], comparing the real index to find the target element.
In a mixed array, the number of index cells in the index table is twice the capacity of the array to store elements. This relationship is maintained during array expansion. For example, if an array can store 8 elements, it will have 16 index cells. The total size of these cells is the size of the corresponding butterfly area in memory.
Regardless of whether it is a packed array or a mixed array, their minimum capacity is 8 elements, and each expansion doubles the capacity. Specifically, the structure storing a single element in a PHP array is Bucket, defined as follows:
1 2 3 4 5
typedefstruct _Bucket { zval val; zend_ulong h; /* hash value (or numeric index) */ zend_string *key; /* string key or NULL for numerics */ } Bucket;
Bucket.val: Stores the value corresponding to the element.
Bucket.h: Stores the integer index.
Bucket.key: Stores the key corresponding to the element.
3.5 Variable Assignment
Here, let's discuss the assignment process between two zval *var, *val, corresponding to the parts of the functions zend_assign_to_variable and zend_copy_to_variable in Zend/zend_execute.h. I'll use pseudocode to highlight some important things and omit some less important information.
1 2 3 4 5 6 7 8
// assign val to var if var is refcouted: var_value = get_value_from_zval(var); copy_zval(var, val) if (get_refcount(var_value) == 1) free_value(var_value) else copy_zval(var, val)
The corresponding functions are obviously more complex than the pseudocode I provided, but we don't need to pay attention to most cases inside them. Here, we say a zval is refcounted, which means it corresponds to a value that requires additional memory allocation, such as string, array, and object, while null, false, true, long, and double are not refcounted because their values are directly stored in zval. The core logic of the assignment process here is to pay special attention to the original value of var.
Let me explain what's happening here:
When var is refcounted, we do the following:
First, we record the original value of var with var_value.
We directly copy val to var using copy_zval.
We check if the reference count of the original value of var is 1, if it is, we free the original value of var.
Otherwise, we directly copy val to var using copy_zval.
In step 1.3, if the reference count of the original value of var is 1, it means that this value is only used by var. After var is assigned a new value, its original value is no longer used by anyone and can be freed. The copy_zval function does two things:
Directly copies the value of val to var.
Adjusts the reference count of the value pointed to by val according to the situation.
We won't discuss what situations adjust the reference count for now.
3.6 Copy on Write
It's a common optimization technique. Consider the following code:
1 2 3 4 5
$a = 'aaaa'; $b = $a; echo$b; $b .= 'b'; echo$b;
In the second line, the string 'aaaa' is not immediately copied to the variable $b; instead, the reference count of the string pointed to by $a is incremented. It's not until the fourth line that the previous string is copied again to concatenate the string 'b', and then the new result is written to $b. So how does copy on write determine when to copy? It's simple: you just need to check if the reference count of the value you're pointing to is greater than 1.
These are all the PHP-related knowledge we need to know here.
0x04 Exploitation Overview
Our general approach is as follows:
Construct a fakeZval primitive.
Leak an address from the heap.
Construct an addressOf primitive.
Construct a conditional read/write primitive for the first stage.
Construct a stable arbitrary read/write primitive for the second stage.
Referring to the common techniques used in jsc exploitation, such as fakeObj and addressOf primitives, we will construct PHP-specific fakeZval and addressOf primitives. This article does not discuss further exploitation techniques because they are often templated and commonly discussed in conventional PHP vulnerability exploitation, for saving space.
0x05 Constructing a Fake Zval
The inspiration for this technique comes from the fakeObj primitive used in jsc exploitation.
Recalling our previous ideas:
Trigger an array resize to release the array's butterfly.
Immediately preempt the memory corresponding to this butterfly.
Write null to the structure we preempted.
Here we first clarify two issues:
Where will null be written in the butterfly?
Combining our previous understanding of the assignment process between two zvals, how do we successfully pass the operation of writing null?
For the first issue, it is meaningless; null will be written to the element specified by the index. For example, if I define a mixed array as follows:
For a string, its first 0x18 bytes belong to the header, specifically:
+0x0: reference count.
+0x4: gc information.
+0x08: hash value cache, if this string has been hashed, the resulting hash will be stored here.
+0x16: string length.
The remaining part stores the string content.
So obviously, the location to write 0x40 falls within the string content that we can control. Therefore, we can forge a zval to satisfy the check mentioned earlier in the assignment process, allowing null to be written smoothly to this fake zval.
0x06 Leaking an Address
To bypass ASLR or read/write the content of a specified address, we first need to leak some addresses to accurately locate the ones we need. The process here is a bit tricky; we leverage PHP's weak type conversion. Consider the following code:
In line 3, there is a string concat operation that concatenates $a['a1'] and null. However, neither of them is a string, so there will be a weak conversion here. true will be converted to the string "1", and null will be converted to an empty string. Finally, the string "1" with a value of "1" is written to $a['a1'], so $a['a1'] will hold the pointer to this string. Through the previously mentioned UAF, $a['a1'] actually resides in the memory we can control (i.e., $user_str), which corresponds to the zval we constructed using fakeZval. By reading $user_str, we obtain the address of this string.
At this point, the memory layout of $user_str should be as follows:
Note that 0x3 inside represents that this fake zval is a true. Because this fake zval is just a value waiting to be assigned, it's just a null, not a refcounted type value mentioned earlier. Therefore, the assignment process here is very simple:
Copy the address of string: "1" to zval.value.str of the fake zval.
Modify the type of the fake zval to is_string.
Note that there is a minor issue here; you will notice that the leaked address of the string does not reside on the heap managed by PHP itself, used to store various PHP runtime structures, but rather on the heap managed by glibc through malloc/free. This is because of a minor optimization by PHP for strings. PHP pre-allocates strings for common strings. If these strings are encountered during runtime, they are simply returned from the pre-allocated ones, avoiding frequent allocation. These strings appear in PHP as persistent strings, and their memory is allocated through malloc.
The weak conversion of true corresponds to the single character "1", which happens to be one of these known strings, and when concatenated here, it's an empty string. This results in the final value being this known string. If we want to obtain an address on PHP's own heap, we must bypass it. It's simple; we can use int or double as the value of the fake zval. Here I'm using int: (100), and later I'll explain why 100 is used.
0x07 Obtaining a Block of Memory
Currently, we have the address str100_addr of string: "100". Let's first take a look at the memory layout of string: "100":
The 0x303031 at content actually corresponds to the string "100". Imagine if we could construct a zval using the fakeZval primitive, let its type be string, and make its value point to str100_addr + 0x8, which is the position of fake_string in the above diagram. Starting from fake_string, we construct a new string with a length of 0x00007fff00303031. The 7fff appearing here is some random data on the heap, and 0x303031 is greater than the capacity of a memory chunk in PHP, 0x200000, so this fake_string can cover the entire memory chunk. This is why I used int: (100) earlier.
Our idea is: Can I use this fake_string to read the content behind the memory? Then I need to obtain this fake_string, as follows:
Line 1 reset_victim_arr_and_user_str() resets $victim_arr and $user_str to ensure that the UAF is triggered later.
Inside the error_handler, we construct a fake zval that points to our fake_string.
Note that in line 15, we use $heap to hold the result of the subsequent array assignment calculation. The result of the array assignment calculation is the concatenation of fake_string with an empty string, meaning that $heap is the fake_string.
We can read the contents of the PHP heap by reading $heap. But that's not all; we can also modify the content of $heap corresponding to fake_string without triggering copy-on-write. Not triggering copy-on-write is crucial here. In theory, if $heap holds the result of the array assignment, i.e., fake_string, the reference count of fake_string should be incremented. If the reference count of fake_string is greater than 1, when we modify $heap, copy-on-write will occur, preventing us from modifying the content of fake_string. Furthermore, we might even cause PHP to terminate when copy-on-write occurs, as the size of fake_string may be large, making it impossible to copy it. For example, referring to the earlier 0x00007fff00303031.
So why doesn't copy-on-write occur here? Let's look at the gc_info of fake_string; its value is the hash of the original string: "100", which is 0x00. PHP checks if a value is refcounted by checking if gc_info is not 0x00. This means that PHP considers fake_string to be non-refcounted, i.e., not an object of interest to the garbage collector. This means that the result of the array assignment calculation is also not refcounted, so there is no copy-on-write here. Copy-on-write only applies to refcounted values.
0x08 Constructing addressOf
Now we have a memory area that is readable and writable, and we know its location. In fact, we could stop here. For example, like the exploitation method in [5]:
Spray a large number of memory structures we want to read on the heap to obtain the addresses we want.
Spray a large number of content structures we want to write to on the heap and write the values we want.
This is how I used it in the first version of exploitation. However, there are still many uncertainties here. For example, if the memory structure we sprayed is not in the memory chunk we can view, the exploitation may fail. In this case, we need to readjust the position of fake_string, such as first spraying a large number of string: "100" to move it to a new memory chunk.
No there's like not sure, I'm the same. Here, we will construct a more stable addressOf to help us locate the positions of memory structures we want. For example:
Control the reference count of this fake array to be 1.
Use the fakeZval primitive to wrap this fake_array.
Trigger the earlier UAF, fake_array is released, and we immediately request the same array $hax to obtain this block of memory.
Suppose the value you want to read is $val, then make $hax[0] = $val.
Then we read the content of the first element of the butterfly on $heap to obtain what we want.
It should be noted that when freeing a small block of memory, PHP first determines the page it belongs to and then determines which bin it belongs to based on its size to place it correctly on the free_list. So you need to determine the position of the fake array you constructed. If you want to bypass this limitation, you can allocate an oversized block of memory to fabricate a memory chunk yourself; you can refer to [16] for details.
0x09 Arbitrary Read/Write Primitive
I set my sights on php://memory [15], where PHP manages a block of memory as a file. The structure controlling the size of this block of memory is:
Arrange a string on $heap that is the size of sizeof(php_stream_memory_data).
Use UAF to release this string, ensuring that fopen("php://memory") obtains a php_stream.
Modify the data pointer, fpos, and fsize above to read/write any area.
Similarly, be sure to release the page where the string is located.
0x0A Full Exploitation
Not provided for now because it has not been patched yet.
0x0B Conclusion
We have analyzed the issues in PHP IR and why they have not been fixed for a long time, and finally proposed a fix suggestion. I also wrote about three butterflies that helped me during my exploration of this issue. Finally, I shared my exploitation methods, attempting to transplant common primitives from JS engine exploitation to PHP. Once I stepped out of the misunderstanding, many ideas were born during the construction of the exploitation process. In fact, this is not a particularly difficult exploitation; it's just that I am a bit slow. I believe that there are many similarities in the exploitation of different interpreters or compilers, which can be mutually learned and studied, and may help you find more ideas.
Finally, the "The Elegy of PHP" in the title is more of a farewell to the past. In the future, I will pay more attention to the new JIT compiler that PHP may release soon and hope to bring you some interesting stories about it in the future.
我又发现了作者有许多关于JavaScriptCore (jsc) 的研究,我之前是没有接触过jsc,只短暂接触过V8。感觉似乎挺有趣的,那就来感受一下吧。在文章[7]和系列文章[8]的帮助下,使得我的博客中又多了一篇《CVE-2018-4262: Apple Safari RegExp Match Type Confusion by JIT》。在这过程中积累了一点点关于jsc的姿势。特别地,里面的部分构造(box/unbox)让我大开眼界,可谓是相当之精彩,以至于后面在PHP的构造中我都想重现它。 jsc里面有一个用来作为存储JSObject的properties和elements特殊结构叫butterfly, 因为其内存结构像一只带翅膀的蝴蝶,顾名butterfly。ascii graph来自[9]
// assign val to var if var is refcouted: var_value = get_value_from_zval(var); copy_zval(var, val) if (get_refcount(var_value) == 1) free_value(var_value) else copy_zval(var, val)
Values may be unboxed primitives (int32, double, or cell), or boxed as a JSValue. For boxed values, we may know the type of boxing that has taken place. (May also need bool, array, object, string types!)
总之就是一句话Storing our value as a JSValue is necessary. 可以尽可能地优化掉encode/decode带来的performance. 在这里作为函数返回值, Caller可能不能准确地预知它的类型, 那么统一将其视为JSValue, 所以这里需要一个boxDouble过程. 使得即使这里是一个Pointer, JSC依然认为其就是一个double-floating point.
var convert = newArrayBuffer(0x10); var u32 = newUint32Array(convert); var u8 = newUint8Array(convert); var f64 = newFloat64Array(convert); var BASE = 0x100000000;
if (file_exists("m2.phar")) { unlink("m2.phar"); }
$phar = new Phar('m2.phar');
// size of target UAF bin is the size of zend_closure $dir_name = str_repeat('C', 0x140 - 0x1); $file_4096 = str_repeat('A', PHP_MAXPATHLEN - 1).'B';
// create an empty directory $phar->addEmptyDir($dir_name);
// create normal one $phar->addFromString($dir_name . DIRECTORY_SEPARATOR . str_repeat('A', 32), 'This is the content of the file.'); // trigger overflow $phar->addFromString($dir_name . DIRECTORY_SEPARATOR . str_repeat('A', PHP_MAXPATHLEN - 1).'B', 'This is the content of the file.');
注意我们使用 "结点" 指特定的generator. 我们可以将内部没有yield from语句, 且也不是其他generator的delegated generator的generator视为一个tree of single node, 即只有一个结点的tree, 其root结点就是它自己. 为了进一步节省篇幅, 我将直接使用tree来指代delegated generator tree.
PHP内部使用如下结构连接tree上的结点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
struct _zend_generator_node { zend_generator *parent; /* NULL for root */ uint32_t children; union { HashTable *ht; /* if multiple children */ struct {/* if one child */ zend_generator *leaf; zend_generator *child; } single; } child; union { zend_generator *leaf; /* if > 0 children */ zend_generator *root; /* if 0 children */ } ptr; };
function search_multi_children_node(gen){ while (gen.node.children == 1) { gen = gen.node.child.single.child; } return gen.node.children > 1 ? gen : null; }
function merge_child_nodes_to_ht(gen, mutil_children_node, gen_single_child_node){ foreach (mutil_children_node.node.child.ht as leaf => child) { ht_add(gen.node.child.ht, leaf, gen_single_child_node); } }
function update_tree(gen, leaf){ root = leaf.node.ptr.root root = get_child(root, leaf);
while (root is finished && root != gen) { root = get_child(root, leaf); } if (root.parent != null && parent is not finished) { do { root = root.node.parent } while (root.node.parent) }