PS:读的同学需要有一点ROP的基础
Abstract
Abstract—As existing defenses like ALSR, DEP, and stackcookies are not sufficient to stop determined attackers fromexploiting our software, interest in Control Flow Integrity (CFI)is growing. In its ideal form, CFI prevents any flow of controlthat was not intended by the original program, effectively puttinga stop to exploitation based on return oriented programming(and many other attacks besides). Two main problems haveprevented CFI from being deployed in practice. First, many CFIimplementations require source code or debug information thatis typically not available for commercial software. Second, inits ideal form, the technique is very expensive. It is for thisreason that current research efforts focus on making CFI fastand practical. Specifically, much of the work on practical CFI isapplicable to binaries, and improves performance by enforcing aloosernotion of control flow integrity. In this paper, we examinethe security implications of such looser notions of CFI: are theystill able to prevent code reuse attacks, and if not, how hard is itto bypass its protection? Specifically, we show that with two newtypes of gadgets, return oriented programming is still possible.We assess the availability of our gadget sets, and demonstratethe practicality of these results with a practical exploit againstInternet Explorer that bypasses modern CFI implementations.
0x00 文章的贡献点
- 评估现有的CFI技术,证明它们并不能有效的防御一些高级的ROP攻击
- 提出一种针对CFI的普遍绕过技术
- 在realworld里面使用了这种技术
0x01 CFI技术背景
理想CFI
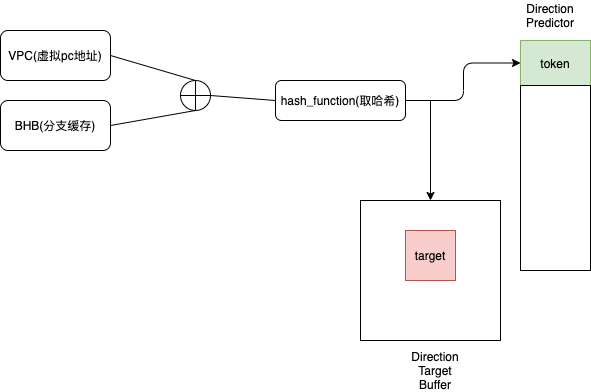
所有的程序控制流传输过程可以分为:直接跳转(direct jmp)和间接跳转(indirect jmp),direct jmp是硬编码的一个fixed address,所以没必要对它做额外的检测,而indirect jmp指向目标可能并不固定,这时候需要根据程序本身的CFG或者CG收集一张可能指向的目标地址列表,在跳转之前插桩检查实际目标地址是否在这个列表里面。对每一个可能成为target的instruction设置一个unique id,前面这张表就可以存储目标地址所在的instruction的unique id.
构建理想状态下CFI会有一些问题: 比如需要绝对精准的CFG和CG图,同时还有一个不能忽视的问题是性能问题,例如target list 是一个很长的表,可以想象频繁调用这个indirect jmp可能带来的问题。
部分CFI
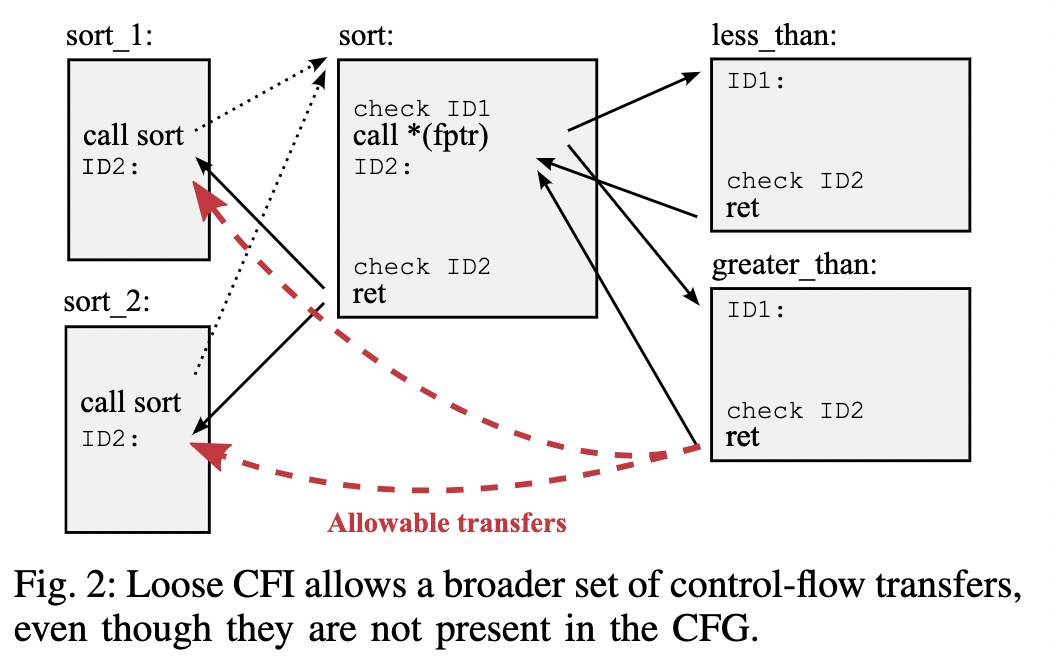
尝试聚合unique ID,没有必要给每一个可能成为target的instruction设置一个unique id. 同样完整的CFG也是重中之重(pointer analysis 就显得尤为重要),那么怎么解决这个问题呢? 研究人员想了一个非常极端的方法,将控制流可能传输到的位置分类,主要是根据indirect jmp的类型: function calls,returns ,indirect jmps. 所有把indirect calls target 定为 functions, 把ret target 定为 instructions follow funtions call(注意这里的函数是指所有出现在当前程序里面的函数), 前面这一串叙述就是在说indirect call的目标地址只能是函数的开头和ret指令的目标地址只能是某个call指令后面的指令.
这个解决方案,个人觉得算是一种妥协吧,把所有合理的indirect jump target都收集起来,针对这个方法,后续就提出一些有趣的改进,transfer 意味着传输关系的start端:

weekness
作者在文中提出了一个ideal CFI下依然存在的缺陷,就算是完整的CFG,也不能提供运行时的sensitive context,我举个小例子,a -> b,c->b都可达,在实际runtime阶段调用a->b,但是b在return的时候并不能保证它的return到caller也就是a,因为这个静态CFG提供的映射关系并不是单射。在更普通的情况下,如果只用两个IDs来实现CFI,其中红线就是可能会出问题的地方。
0x02 在CFI下实现ROP
CFI下可用的gadget
Call-side gadgets : 紧跟着call/indirect jmp 指令后面的gadgets
Entry-point gadgets: 函数入口处的gadgets
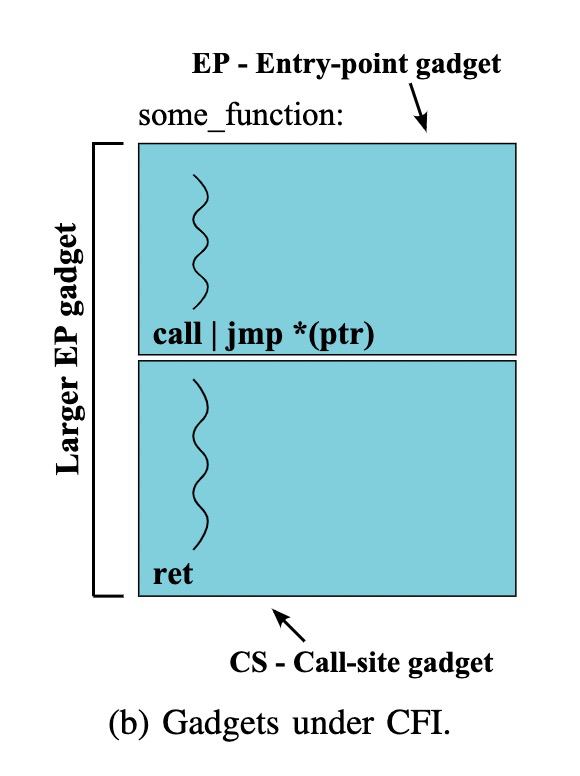
这类gadget都是indirect 跳转下allowable target的开头,不同于正常情况下的gadget,它们的起始需要一点限制,并且这可能导致这些gadgets的大小变的不可控。作者提到这种gadget中还可能包含一些分支路径,如果这些分支路径的条件我们可控,那么是可能去跳过执行某些代码,这可以使得一个gadget多用.
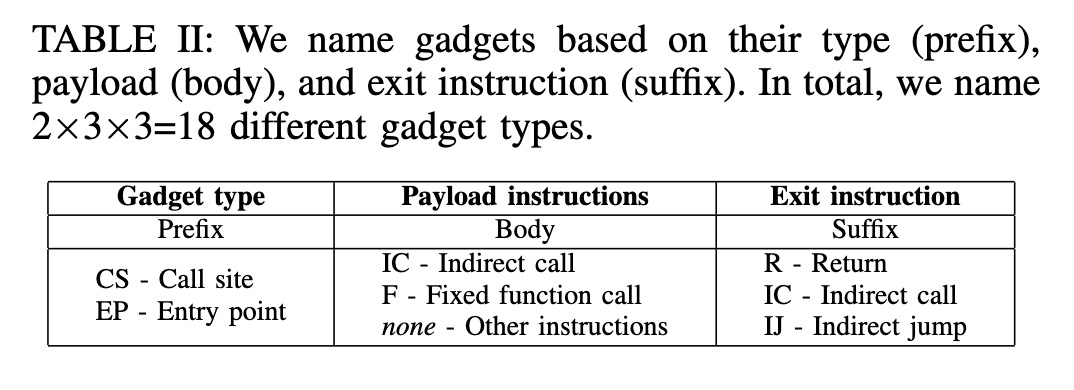
文中将CS类型和EP类型组合而成的gadgets具体的分为了18种,对一个具体gadget的prefix,body和suffix分别进行分类. 这样做的目的是刻画执行一个gadget时控制流可能发生的状态. 如下表:
如何调用函数?
直接通过indirect call :因为indirect call总是允许调用存在的函数,这里的前提是我们有机会直接控制这个call的target。CFI规则越松散,越多的函数我们可以调用。
通过gadgets里面的call指令:直接用一张图来说明:
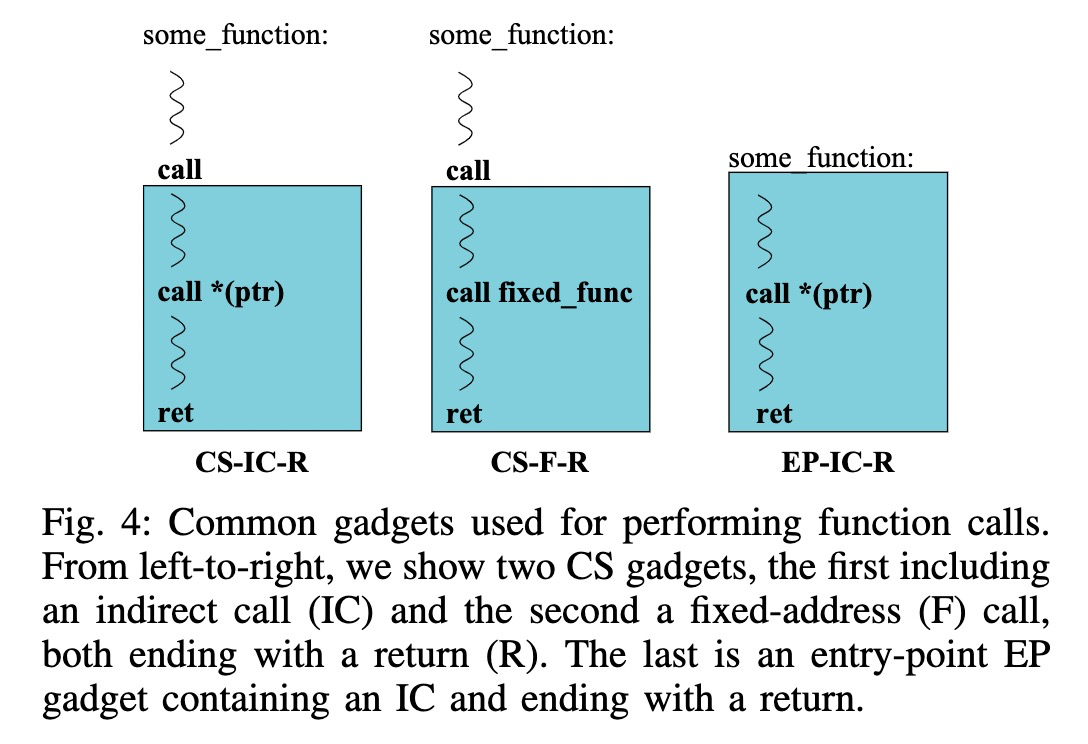
特别的说一下中间这种gadget可能允许我们访问敏感函数,例如CCFIR就对敏感函数做了特殊的处理。
如何连接这些gadgets?
这些gadgets 连接过程需要非常特殊,如果你可以控制ret的目标地址,那这个目标地址就只能是CS后面的指令。
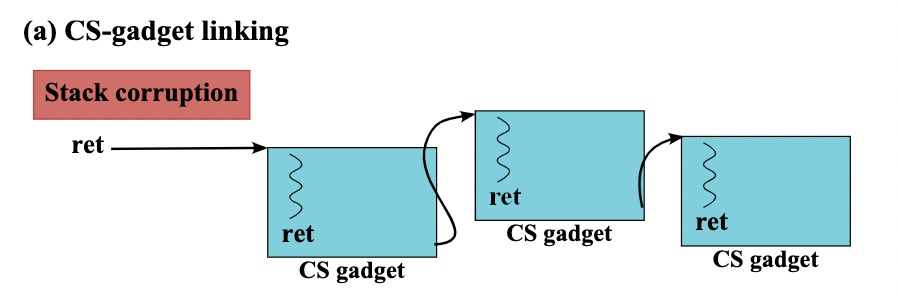
同样如果你可以控制indirect call的目标地址,那这个目标地址就只能是函数入口,也就是说无法做到任意链接,这里的链接过程是有限制的。
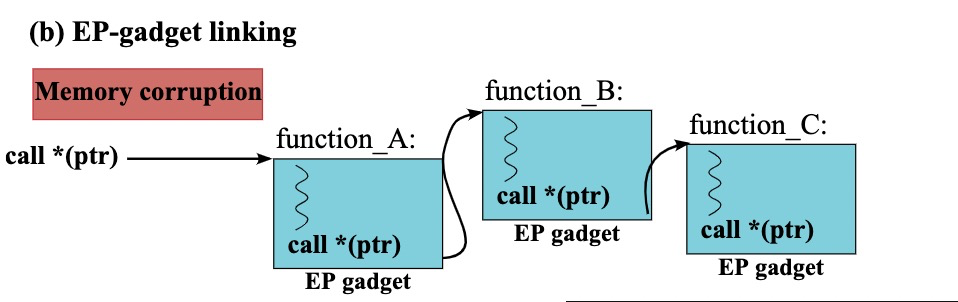
CS和EP两种gadget之间是可以相互转换的,例如EP 转CS: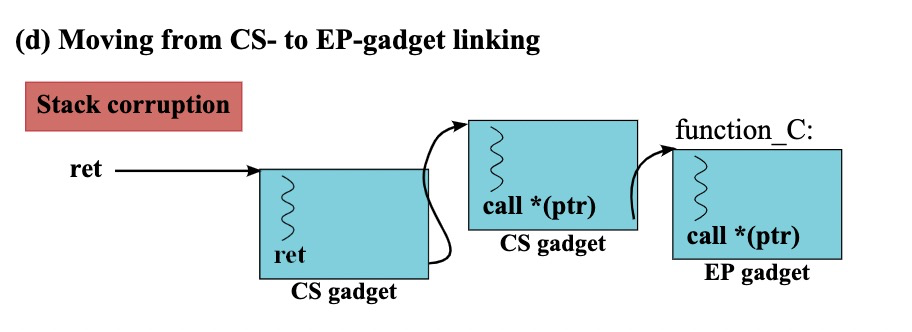
这里有一个细节需要注意,也就是注释框里面提到的,B函数中间的这个indirect call必须要这个ptr合法,这也是前面我提到的为什么要细分两种gadget的中间指令。下面是CS转EP的过程:
从ROP到代码执行
单纯的用ROP来实现getshell是比较难的,文章作者思路是用ROP调整page的权限,然后写shellcode,最后通过间接跳转执行这段shellcode。
0x03 Do it at Realworld
这一节作者利用了一个ie 浏览器的堆溢出来说明他的方法是可行的,关于漏洞具体构造需要自己手动实践,在这里我主要记录几个有意思的东西。
Springboard section
CCFIR里面使用了这个东西,这个东西是一个indirect call的跳板:
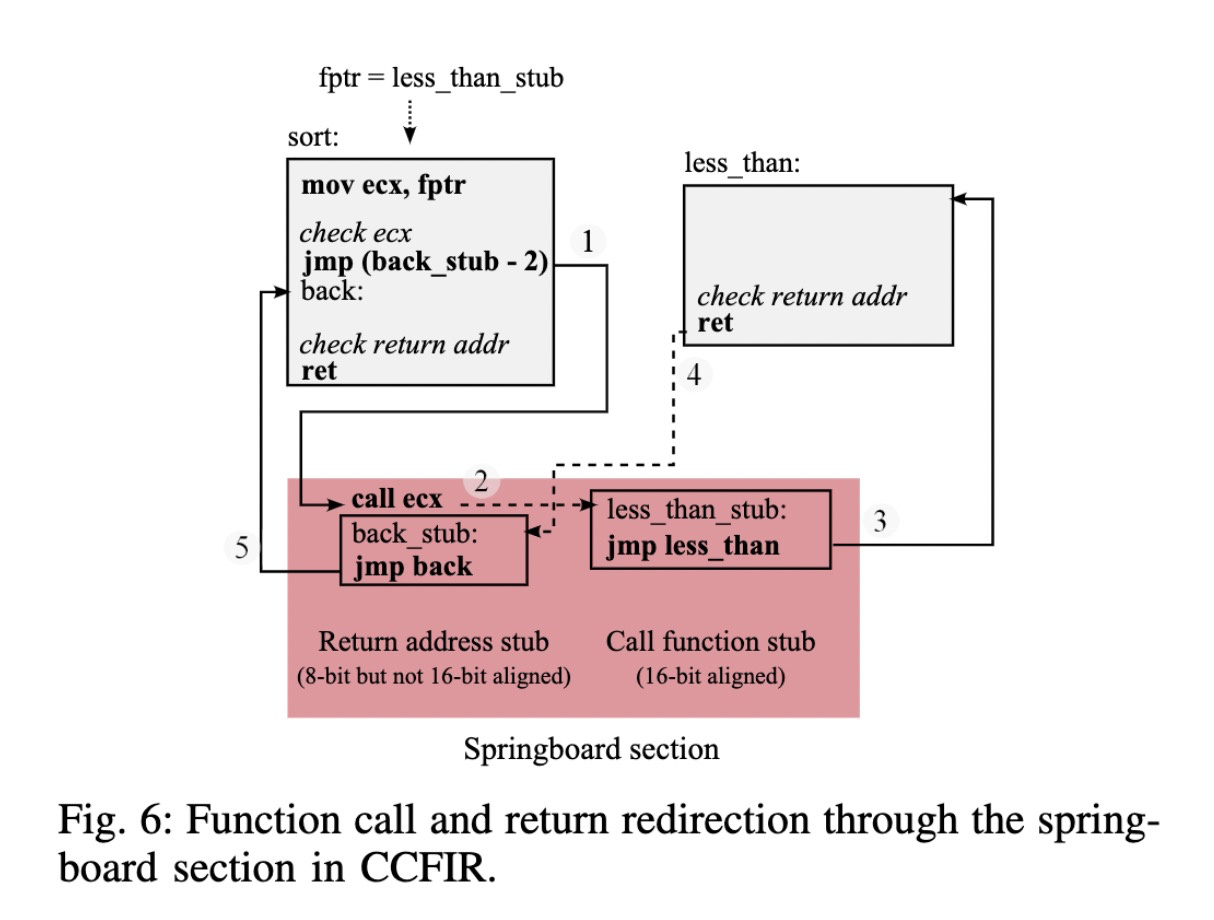
可以看到这里一个indirect call首先变成了一个direct jmp,跳到了这个特殊的Springboard section上,这个设计还是比较精妙的,在这个特殊的section上全程是没有动栈的结构,所以在ret的时候可以不用担心。那么在这种机制下面,check的条件就发生了变化,首先indirect call和ret的目标地址都是在Springboard section上的而且是对齐的,这就对使用gadget来实现函数调用提出了更高的要求,在实现上通过重定位和导出表的信息把指定函数位置替换成了CCFIR自定义的stub地址,其中还提到这个stub位置在加载时候是随机的,这函数调用变得更加困难了,意外着你必须首先泄露这些stub的信息。
主要实现细节
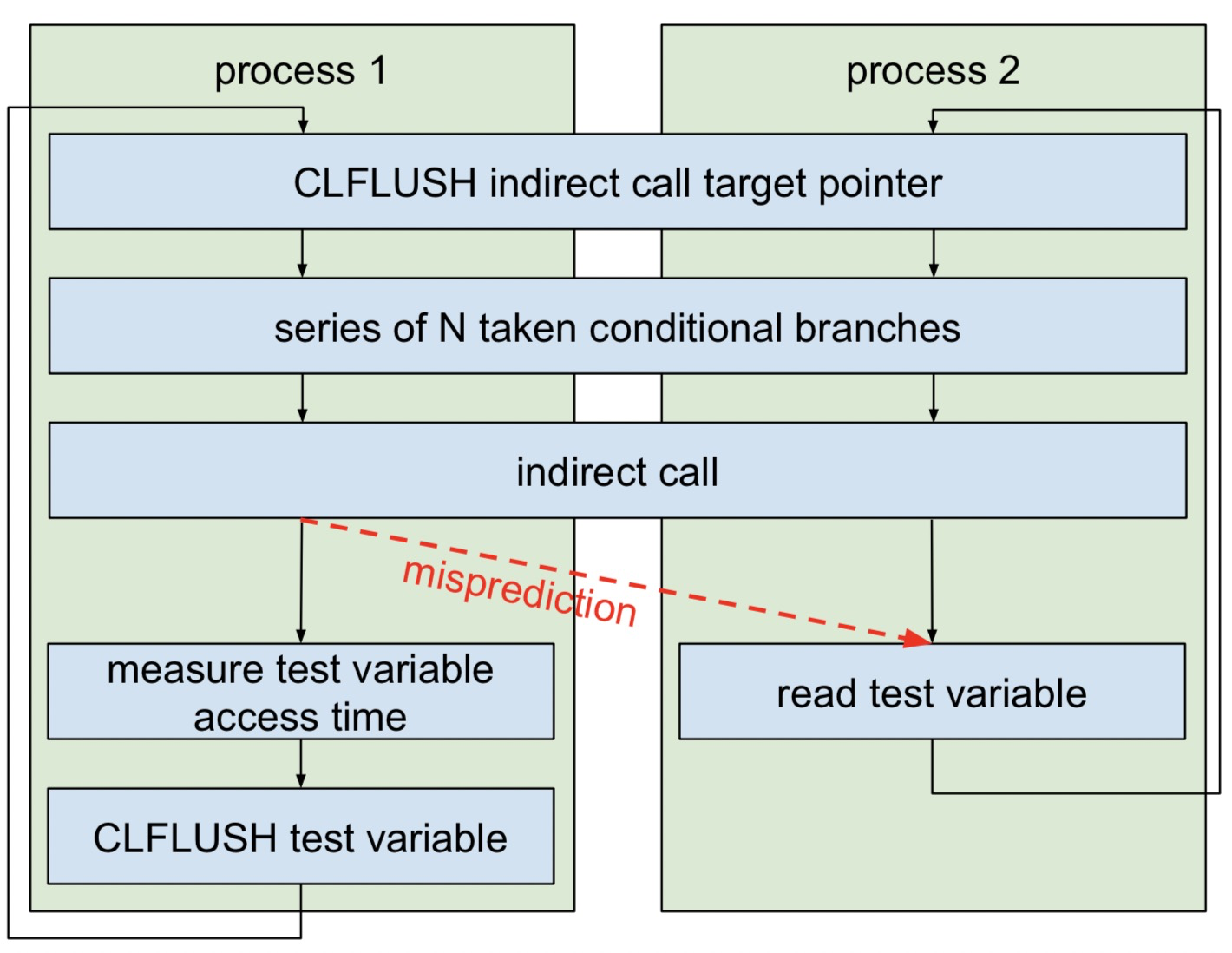
通过这个堆异常,给了attacker控制一个indirect jmp的机会,但是为了实现ROP,作者尝试把这个indirect jmp 变成 retn ,但是还需要一个stack pivoting (我称之为切栈小助手)来保证你有一个可控的栈来执行更多的gadget,后面就是相关函数调用。 这里面出现了几个有趣的问题:
为什么要把这个可控的indirect jmp转换成可控的retn?这过程中遇到了哪些问题?
因为前面我们知道,indirect jmp 只能衔接EP类型的gadgets,但是EP类型gadgets实际并不好利用,CS类型gadgets相对来说更好利用,而且比较多,为了用CS类型的gadgets,就必须需要一个可控的ret才 行。
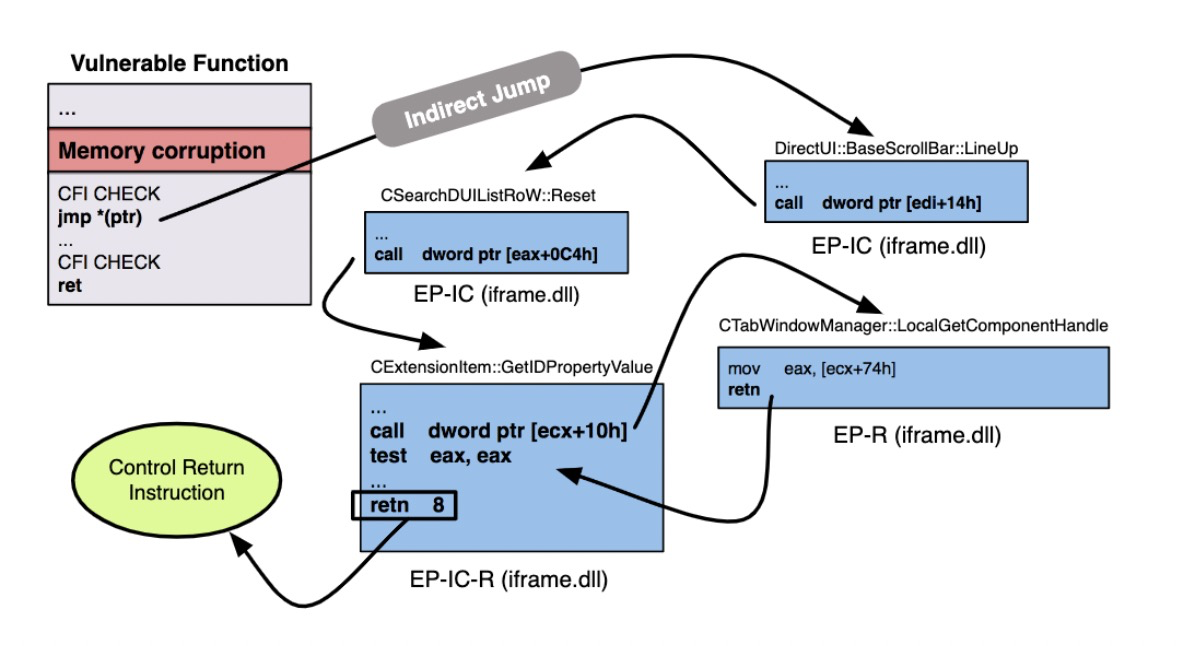 作者通过四个gadgets完成了这件事,在堆溢出这个地方,indirect call控制的是ecx,这个要先了解一下,最后,让我们来一起用欣赏的眼光来看看这四个gadgets!
作者通过四个gadgets完成了这件事,在堆溢出这个地方,indirect call控制的是ecx,这个要先了解一下,最后,让我们来一起用欣赏的眼光来看看这四个gadgets!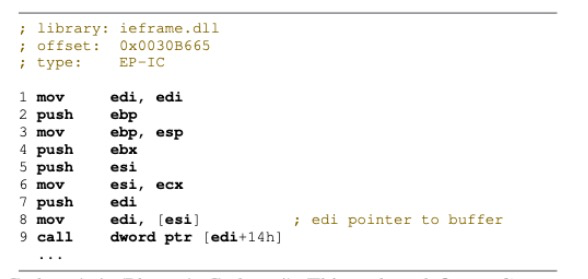
这是图中第一个EP-IC gadget,ecx是我们可控的,间接导致来edi我们可控,最后这个indirect call可控。

这是图中第二个EP-IC gadget,在这个gadget里面没有改变edi的值,edi还是可控的,所以现在还可以控制栈最后结构,最后这个call依赖于eax,而eax同样是被ecx控制。

图中第三个EP-R gadgets,可以用简洁有力来形容,还可以控制返回值。这个gadget主要来用来应对突然出现的indirect call不会报错和其他副作用,就单纯的直接return到caller。

图中最后一个EP-IC-R gadgets,第三个gadget 就可以用在第9行,防止这个多余的indirect call造成其他的影响,这个返回值是否可控依赖于eax,但是这个eax是从是栈上获取的,而且是第一个参数,而这个参数已经在第二个gadget中被控制了,所以最终就完成了对ret的控制。
整个过程用的gadgets虽然不多,都是都比较精妙,非常值得学习!
stack pivoting
有了可控的ret之后,现在可以用CS 类型的gadgets了,为了回到正确的ROP道路上,还需要一个fake stack,注意到在前面的最后一个gadget中,ebp已经是可控了的,因为在pop之前,push 的这个eax是可控的。所以接下来需要改esp,作者找到了一个非常好的stack pivoting,可以直接把esp覆盖成ebp。
 这样就有了完全对stack的控制,后面就是正常通过CS gadgets构造的ROP过程。
这样就有了完全对stack的控制,后面就是正常通过CS gadgets构造的ROP过程。
0x04 Evaluation
作者分析了164个PE文件,提取CS和EP类型的gadgets:
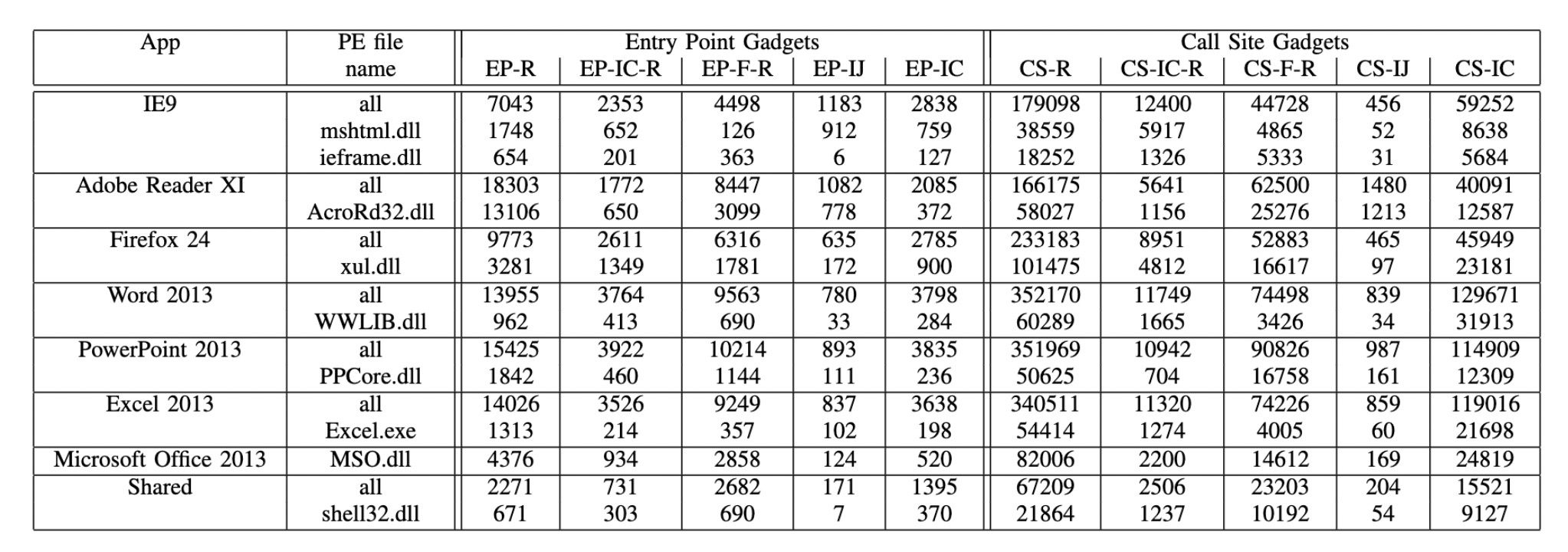
可以看到这一类的gadgets是比较普遍的,CS类型的gadgets要普遍多余EP类型的gadgets,这也是为什么前面要把indirect call 变成ret的主要原因。作者为了执行代码,主要使用了memcpy 和 VirtualAlloc,用来调整page的权限和写入shellcode,同样也分析了一下其他PE文件里面这类包含这些函数调用的gadgets:
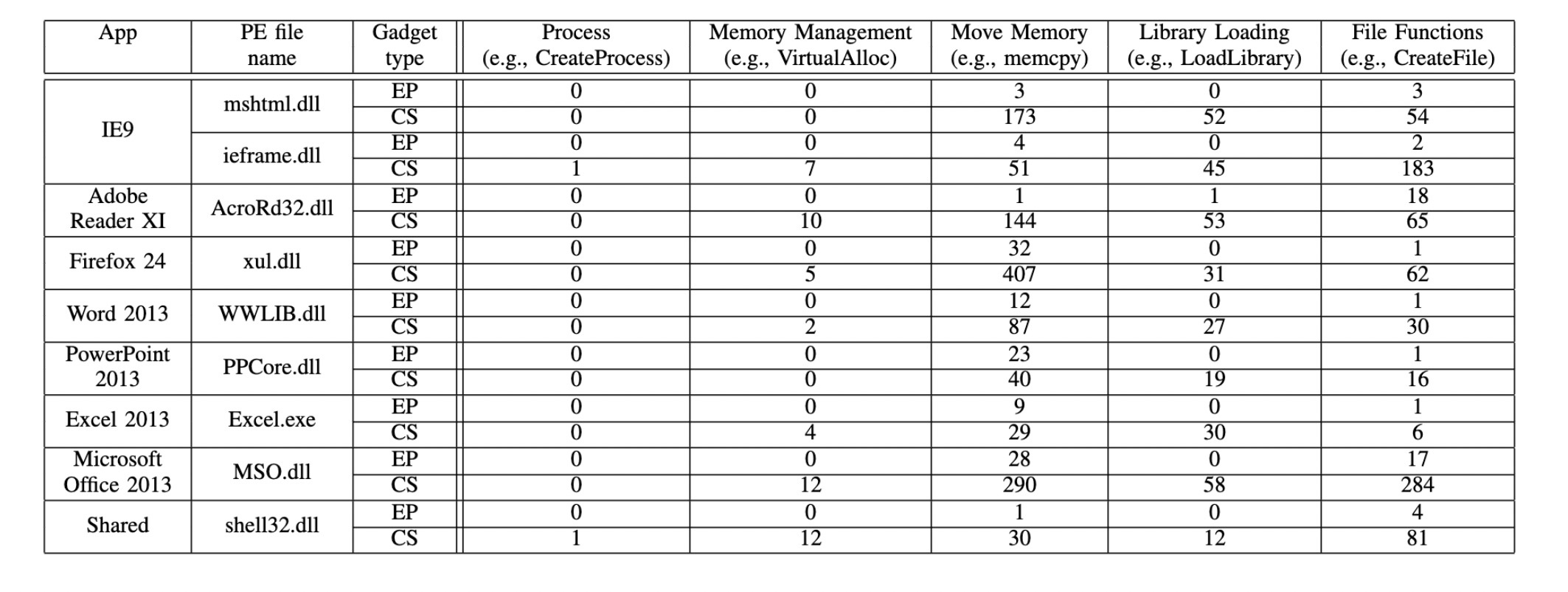
虽然不多,但是有!也能说明一些问题。
0x05 Discussion
一些其他缓解措施:
kBouncer 通过监控进程来检查函数返回地址是否在call指令后面,这一技术需要硬件的支持(Last Record Branch),其还支持一种启发式的算法,用来检查在没有call的情况下频繁的return操作,这样完全用CS-R构造的ROP chain就没法用了,但是CS-IC-R或者CS-F-R还是有可能骗过这个算法的。
G-free 通过二次编译,用一些转换公式消除gadgets,并且不允许直接跳到某个函数中间执行代码。这个方法几乎把所有CS类型的gadgets都整没了。但是EP类型的gadgets依然奏效,但是实际上仅用EP来构造exp在实际中是比较难的。
一些可行缓解措施 在最早的CFI工作中,为了在运行时来实现CFI,构造了一个shadow stack,来保存所有的返回地址,但是这种方法被一些编译优化打破,并不是每一个call都有一个ret所匹配,导致无法在某些情况track the stack。
ROPDefender 也是一种构造shadow stack的方法,但是它关注的是call-ret的匹配,因此如果一个ret没有被相应的call匹配到,就直接报错了,但是也会被上面的情况所影响。
CFL(Control-Flow Locking)通过锁的方式来保证CFI,在indirect tranfer之前lock,如果是合理的target则执行unlock操作,locks和unlocks是配对的,基于源代码的CFG形成的。作者认为这种方法在未来是可行的,可以有效的防治它们的攻击,但是缺陷是如果没源码就做不了。
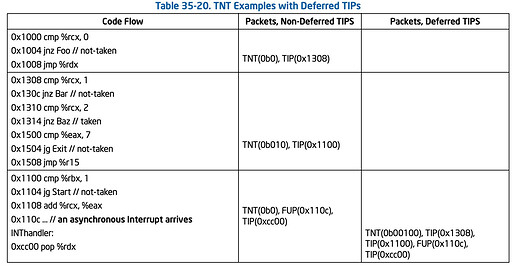






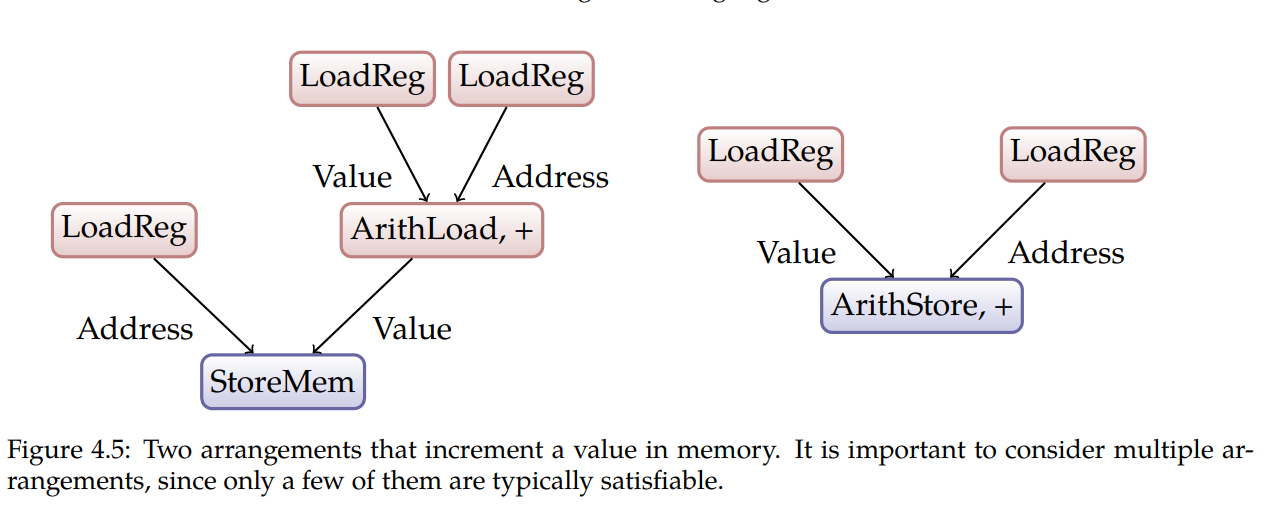


 总共发现了105个漏洞,其中25个是已知的,在其余的80个漏洞中,其中有41个被确定为CVE。
总共发现了105个漏洞,其中25个是已知的,在其余的80个漏洞中,其中有41个被确定为CVE。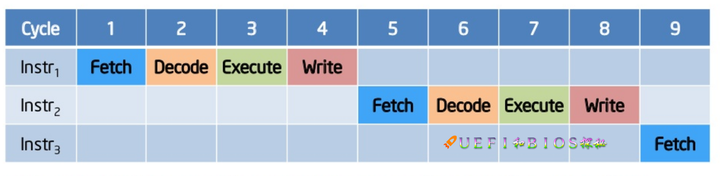 在顺序执行下, 指令将逐一处理,意味着一条指令要等到前一条指令处理完毕后才能被执行。
在顺序执行下, 指令将逐一处理,意味着一条指令要等到前一条指令处理完毕后才能被执行。 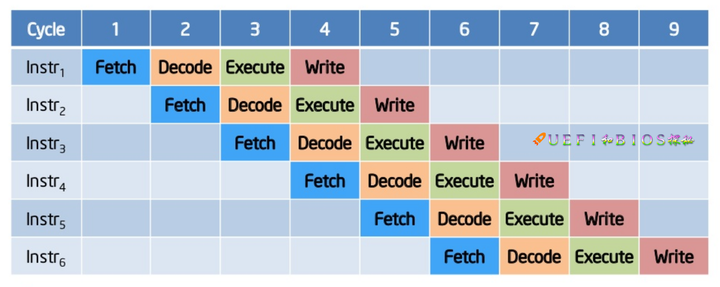 当加入了流水线的技术,我们使用不同的流水线处理不同的指令,比如上图有4个流水线,用来分别处理
当加入了流水线的技术,我们使用不同的流水线处理不同的指令,比如上图有4个流水线,用来分别处理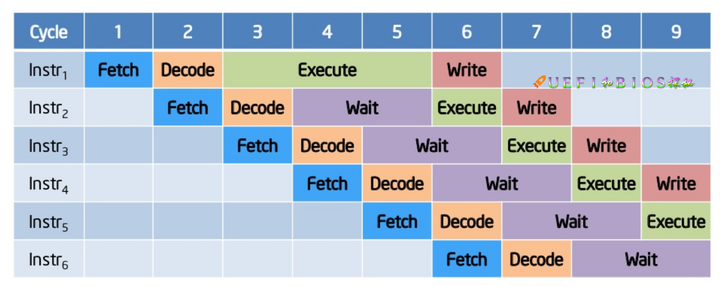 在现实情况下,考虑到每条指令的执行时间并不是相同,或长或短,就会造成上图的这样一种等待现象。
在现实情况下,考虑到每条指令的执行时间并不是相同,或长或短,就会造成上图的这样一种等待现象。 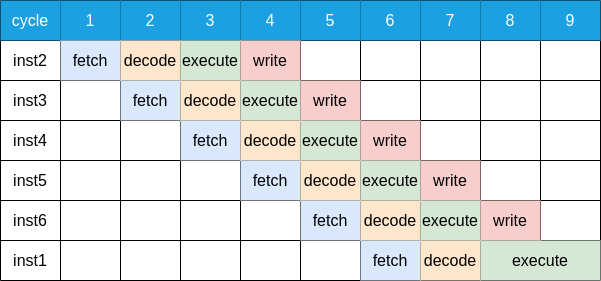 我们考虑这6条指令相互并不依赖, 因此我们可以调整指令的执行先后顺序, 上图中我们把inst1放到了最后, 使得等待现象消失, 流水线被充分地利用了起来. 最后附上一张intel核心处理器的流水线图:
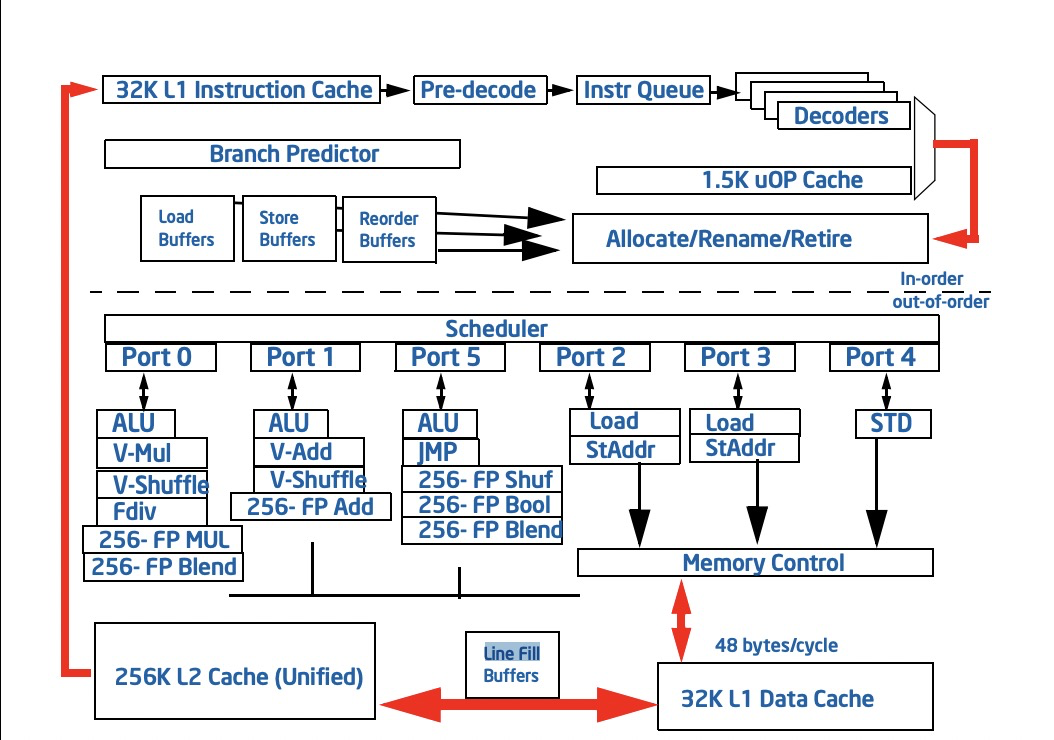
我们考虑这6条指令相互并不依赖, 因此我们可以调整指令的执行先后顺序, 上图中我们把inst1放到了最后, 使得等待现象消失, 流水线被充分地利用了起来. 最后附上一张intel核心处理器的流水线图: 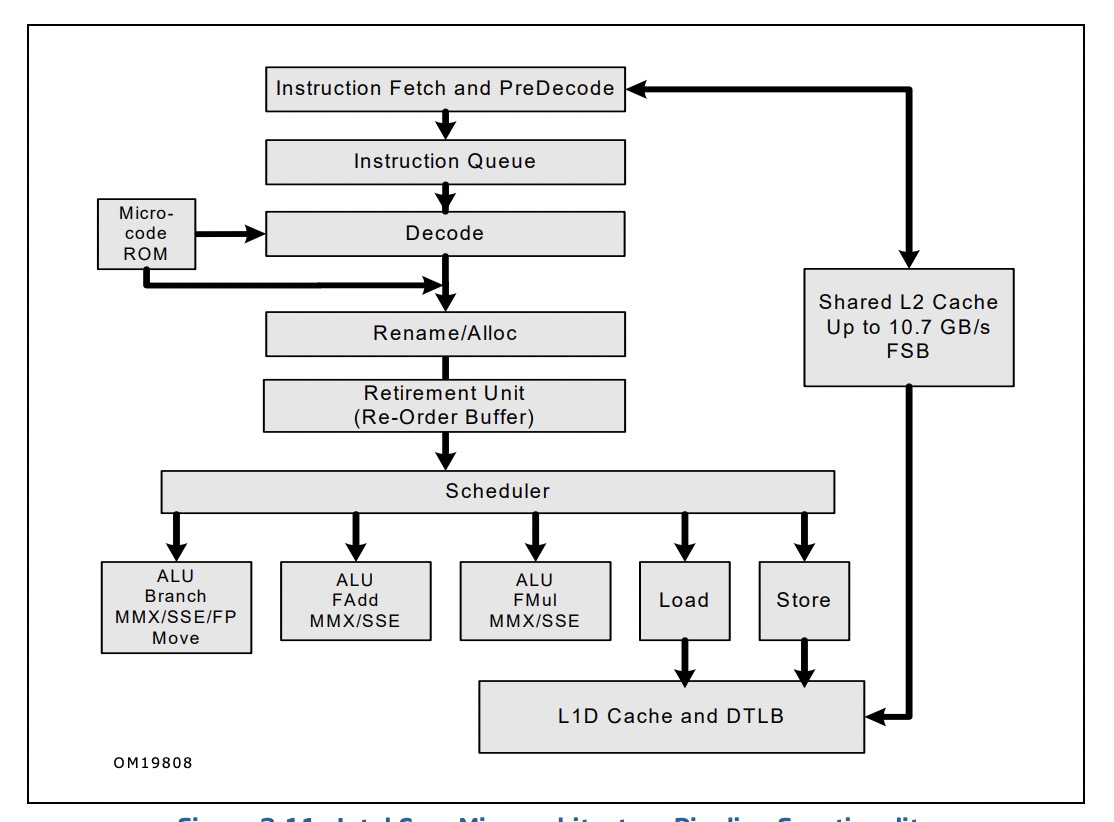
 这里需要了解一下 TLB 和 cache的含义,TLB用于mmu在虚拟地址与物理地址的快速转换,物理内存和虚拟内存通过页交换,物理页和虚拟页的大小一样都是4096,所以虚拟地址上低12位用于在页上偏移。
这里需要了解一下 TLB 和 cache的含义,TLB用于mmu在虚拟地址与物理地址的快速转换,物理内存和虚拟内存通过页交换,物理页和虚拟页的大小一样都是4096,所以虚拟地址上低12位用于在页上偏移。 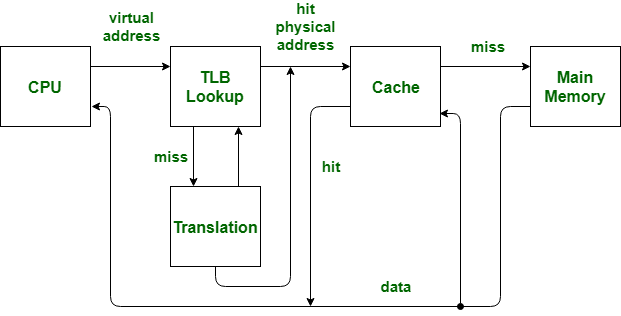
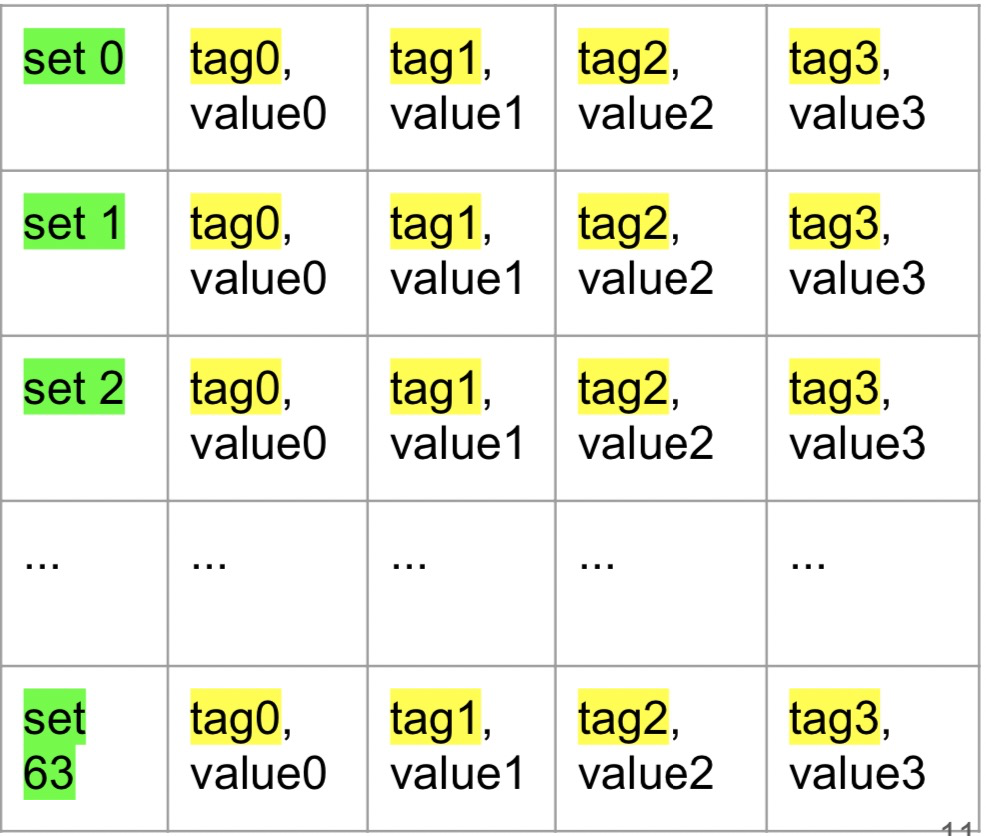
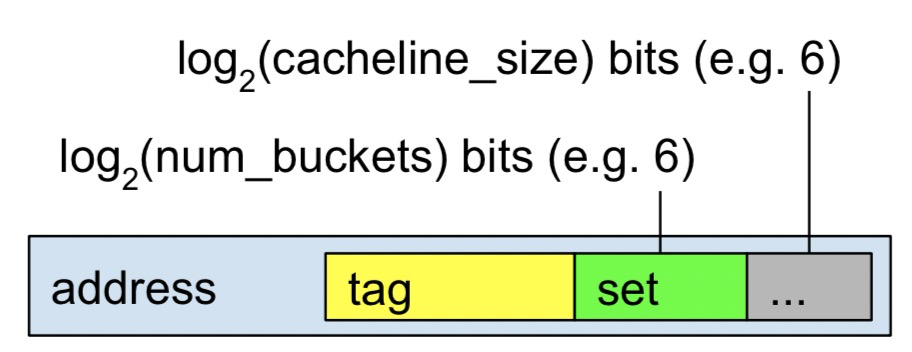 tag只是部分物理地址,cacheline长度一般为64bytes,所以这里低6位用于对齐cache-block,紧接的6位用于标记set,看上去cache有点像hashtable,4路相当于有4个buckets,意味着任意一个cacheline都可能位于这四个cacheline其中一个位置上,这就关系到cache 的插入算法上。如果cache 缓存没有命中就需要去访问主存了,这其中的时间周期就很显然易见了,了解cache的结构有利于后面过程的理解。
tag只是部分物理地址,cacheline长度一般为64bytes,所以这里低6位用于对齐cache-block,紧接的6位用于标记set,看上去cache有点像hashtable,4路相当于有4个buckets,意味着任意一个cacheline都可能位于这四个cacheline其中一个位置上,这就关系到cache 的插入算法上。如果cache 缓存没有命中就需要去访问主存了,这其中的时间周期就很显然易见了,了解cache的结构有利于后面过程的理解。