Abstract
静态的二进制分析相对于静态源码审计是更困难的,因为二进制处于更底层的位置,缺少了高层的抽象,例如变量,类型,函数,控制结构。
提出了一种抽象恢复的静态二进制分析技术
抽象恢复的前提是很多二进制程序是高层的抽象语言编写的,而且抽象的源代码更适合分析。
抽象恢复的两个应用
- c语言形式的反编译
- rop chain的自动生成
抽象恢复并不能应用到所有的二进制分析。
Overview
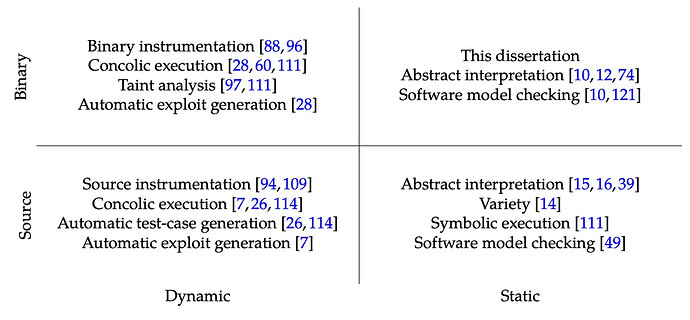
静态分析和动态分析对比
- 准确性
- 动态分析建立在程序执行的基础上,是程序真实存在的行为。
- 覆盖率
- 动态分析的输入可能无法覆盖所有程序路径,可能会导致一些bug的miss,但静态分析可以充分考虑这些路径。
- 环境影响
- 静态分析需要对外部环境建模,例如syscall,外部函数调用等等。
- 副作用
- 静态分析可以避免待测程序运行起来对系统的影响。当待测程序是untrust的时候这非常有必要。
- 准确性
二进制分析的优点
- 终端用户适用性
- 二进制分析可以有效的适用于所有可以运行的二进制,而不需要知道源码。
- 未定义行为
- 在source 层面,可能有一些语法是比较模糊的,但是在二进制层面,我们可以知道它真正的执行过程,比如一些agressvie optimizers可能造成一些优化带来的安全问题。程序的最终运行还是依赖于编译器,优化程度,flags 等等。
- 二进制特征
- 有一些程序只能在二进制层面分析,因为关注的属性并不在source层面。比如automatic exploits generation(AEG),需要自动化的检测漏洞并构造exploit,AEG需要了解stack frame分部和padding的信息。
- 语言无关
- 二进制分析可以适用于不同语言编译出来的二进制程序。从长远来看,可以避免单独给每一门语言写一个独立的analysis tool,是一种非常不同的选择。
- 终端用户适用性
二进制分析中的挑战
- 复杂的语义
- 一些汇编指令是具有副作用的,比如在条件跳转时,需要flag的信息。如果完全考虑这些情况,对每个汇编指令建模时,将非常复杂。
- 抽象的缺失
- 基于source层面的静态分析是无法直接用到二进制的层面的,在编译过程中移除了variables,types,functions,control-flow structure的相关语法结构,而生产一些实际指令,基于实际指令的分析要难于对抽象语法的分析,例如一个局部变量,在source里面有明确的定义,在二进制层面就被放在栈上,可能难以通过栈的结构去区分这些局部变量。
- 通过不同语言编译出来的二进制,难以在二进制层面有一个自然表示。
- 间接调用
- undecidable problem
- unsound:导致不完整的CFG 或者 过于冗余的CFG
- 复杂的语义
现存二进制分析的方法
中间语言
Binary Analysis Platform(BAP)
可以显示的把机器语言产生的副作用flag表示出来

控制流重建
- 尝试处理间接调用,恢复CFG
抽象恢复
前提:(1 二进制程序通常是从高层的抽象语言编译而来 (2 这些高层的抽象语言更适合做静态分析
方法论:(C or gadget abstractions)
- 已被编译的应用通过抽象恢复 计算出 抽象程序的行为中可观测的属性
- 通过抽象恢复再分析要比直接分析应用更快
最大的motivation: the success of static source analysis
源程序 和 二进制程序最大的不同:抽象层次的不同
Source-code Abstractions
反编译器应该关注的两个方面:
- 从实际分析出发,尽可能恢复有利于后续分析的抽象表示。
- 保证抽象恢复的结果是正确的。
反编译器主要恢复两种抽象类型:
- 数据类型抽象
- 控制流抽象
Phoenix的控制流结构化算法基于structural analysis
- semantics-preservation
- iterative refinement
背景知识:
控制流分析:
- 控制流图用
形式化的表示,其中 表示BB集合, 表示edge集合, 表示entry, 表示exit - Domination
dom ,表示从 到 的每一条路径都经过了 pdom ,表示从 到 都每一条路径都经过了 - immediate dominator : 这个
是唯一, 只是 的dominator。eg:f -> d -> n, f和d都是n的dominator,但是d是n的immediate dominator。关于 immediate post-dominator的定义反之亦然。 - Loops 定义:若 edge
是一条后向边,则 dom ,每一条后向边都可以来定义一个头是 的natural loop。 - natural loop 定义: 一个具体的naturl loop是指可以不通过
到达 的所有node的集合和 本身。
- 控制流图用
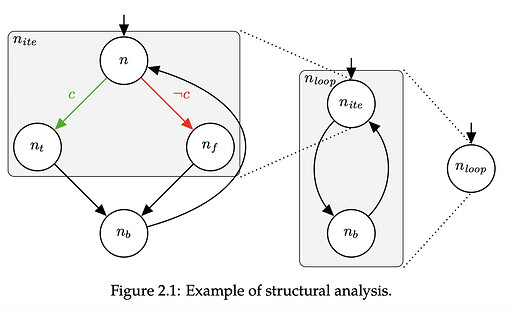
Structural Analysis:
解释:Structural Analysis 是一种用来恢复高层控制结构的数据流结构结构化的算法,eg:if-then-esle,loops。
SESS Analysis and Tail Regions:
motivation:由于Structural Analysis 是无法识别C循环结构中的break和contiune,提出了single exit single successor(SESS)来标识存在这样的退出状态的语句。
方法:将exit状态转化成tail regions。eg:body;break; 将转化成一个tail regions
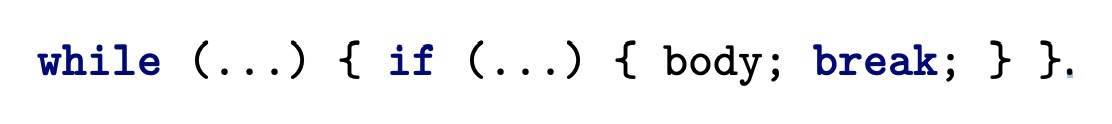
Overview:
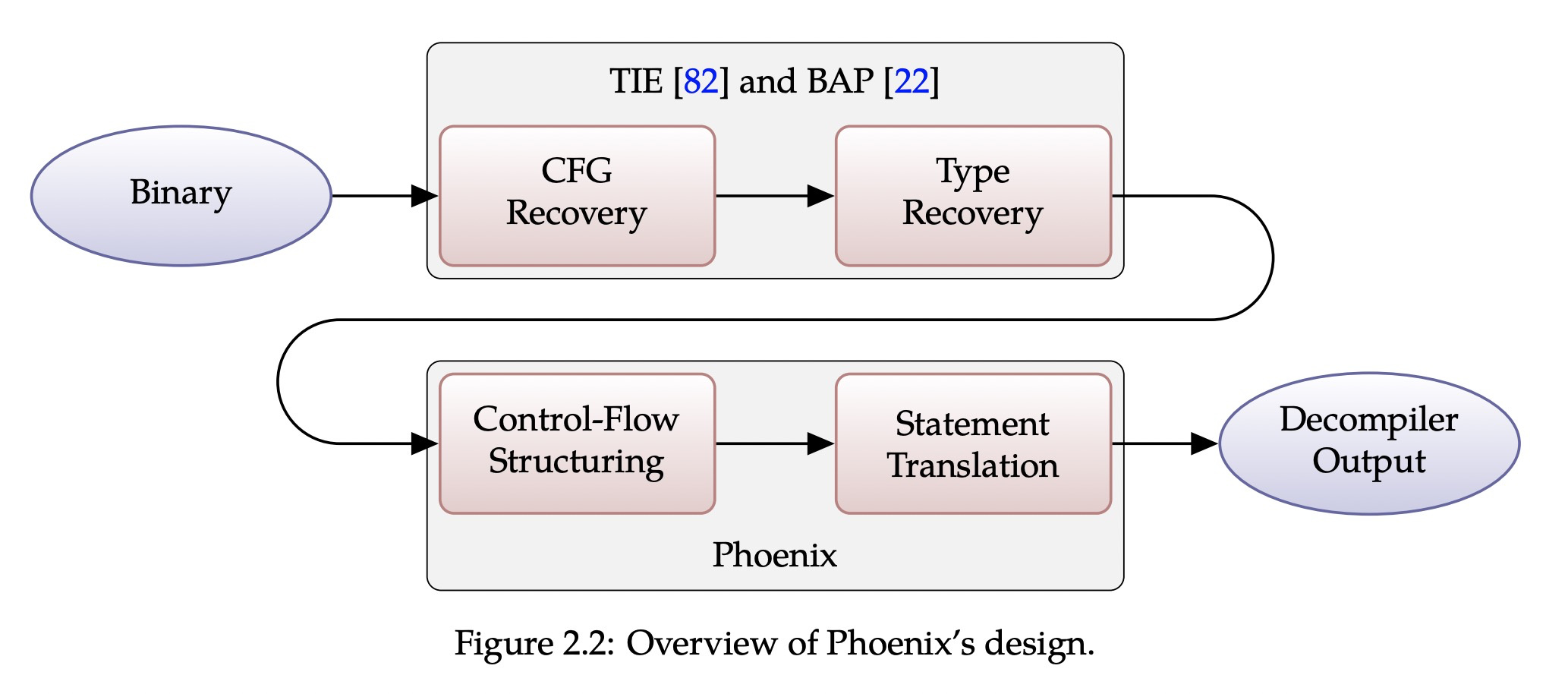
控制流图恢复:
- 使用BAP,生成BIL。
变量和类型恢复:
- 使用的TIE( TIE: Principled reverse engineering of types in binary programs),TIE使用Value Set Analysis(WYSINWYX: what you see is not what you execute)来恢复变量地址,然后对变量使用基于静态和条件约束类型推导。
控制流结构化恢复:
- 以CFG作为基础,在CFG中寻找结构化的shape,相对于在CFG中刻画了一个子图。
- 两个特征:
- 迭代细化
- 语义保留
语句翻译(C格式):
- 在CFG上通过对节点结构化的标记,需要把每一个节点所对应的BIL语法翻译成更高层的HIL,eg:比如翻译函数调用,翻译器通过callside处的栈指针,并使用类型信息来计算传参数量。
- 优化可读性:
删除冗余的死代码
untiling optimization (不知道是什么?)
tiling: 使用源语言的ast,让汇编语言尽可能的覆盖语法节点,比如
,首先用一个add指针来填充y+z,然后使用一个div指针来覆盖除法。 untiling algorithm :输入一些statements,输出相同语义的高层次的statements,eg:
表示从a&b中提取最高位的1,等价于 ,(我没有理解这里的等级关系)
语义保留结构分析和迭代式的控制流结构化
语义保留:
- motivation:structural analysis可以识别出与CFG可达性一致的控制流,但是无法识别于CFG语义一致的控制流。(if-true-false)eg:当x=1 和 y=2时,在源CFG上,在x=1时已经退出loop,但是在中间图上,y=2也可以退出loop,这显然是不对的。
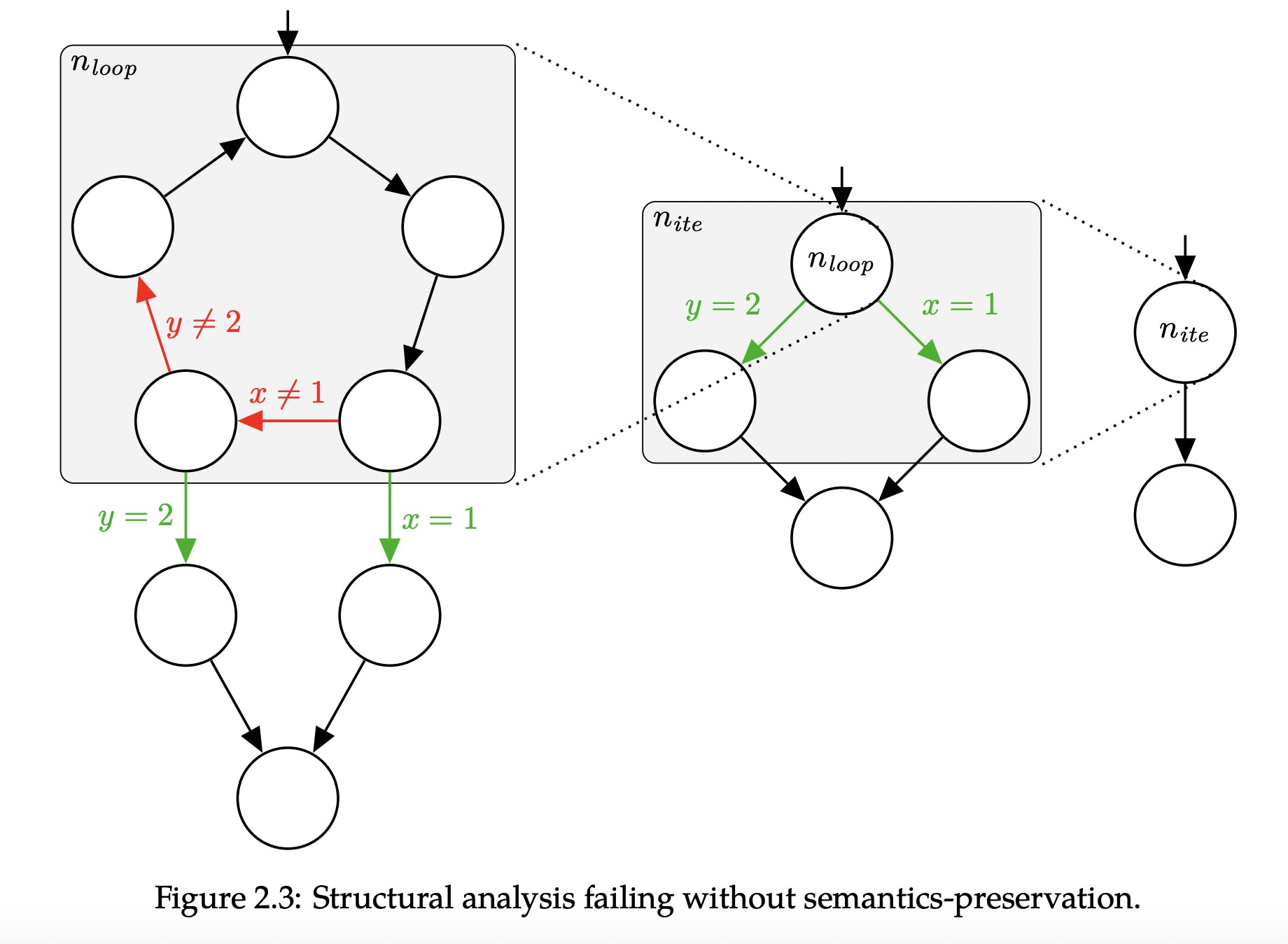
- motivation:structural analysis可以识别出与CFG可达性一致的控制流,但是无法识别于CFG语义一致的控制流。(if-true-false)eg:当x=1 和 y=2时,在源CFG上,在x=1时已经退出loop,但是在中间图上,y=2也可以退出loop,这显然是不对的。
方法:在structural analysis中很多结构化的策略都是保留语义的,但是loop这样的结构化策略,是会忽略语义的。Phoenix通过把这些会丢失语义的策略,替换成保留语义。
迭代细化
refinement : 在CFG上去掉边,并在对应地方加上goto语句
Iterative Refinement:重复执行refinement过程,直到可以结构化可以运行。
refinement 工作要额外小心,eg:判断b[i]会不会造成溢出,需要考虑i的取值,i是一个循环不变量。如果将while换成goto,可能就无法识别这个地方是安全的。

算法概览
- 无环模式(当前处理的node 处于无环控制流里面)
- acyclic schemas
- switch region
- 环模式 (当前处理的node 处于环控制流)
- cyclic schemas
- loop
- 无环模式(当前处理的node 处于无环控制流里面)
无环区域
无环区域定义:C语言中无环控制流操作,指令序列,条件跳转,switch
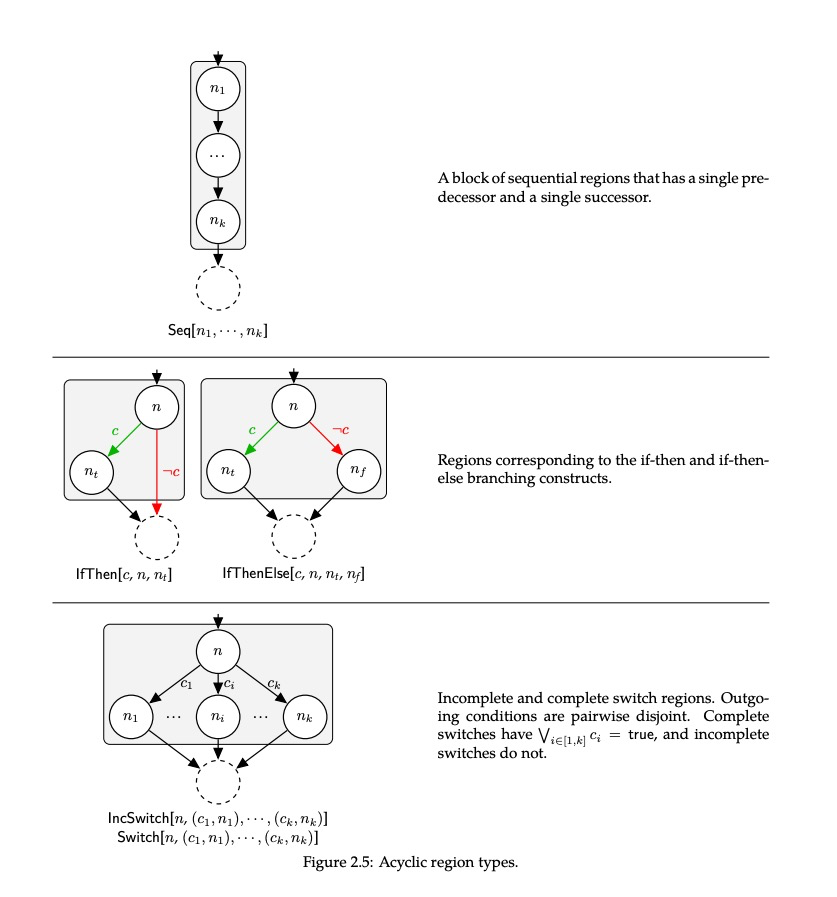
从直觉上如果仅靠shape的定义是很难区分控制流结构,例如一个switch 有两个case x=2 和x=3,其实他也是满足if-then-else结构的,但是if-then-else需要有完全相反的条件。
尾部区域和虚拟边
motivation:可能在CFG上以某点n为子图无法匹配任何区域,提出了refine的概览,可能通过尝试去掉CFG上的某些边,可以去匹配一些控制流,这个称为refine 迭代过程,直到某次refine之后可以匹配某一个控制流结构以后,就停止refine。
虚拟边:去掉CFG上一些边以后可能改变语义,虚拟边的就是用于在保留语义的情况下去掉一些边。分为两种情况的边:
- 带条件的有向边
- 无条件的有向边
例如
是无条件的边,当去掉这条边以后,在 出标记一个标签l,再将 标识为 .这样结构再后面可能会被翻译成break 或者 contiune。 
switch 精修
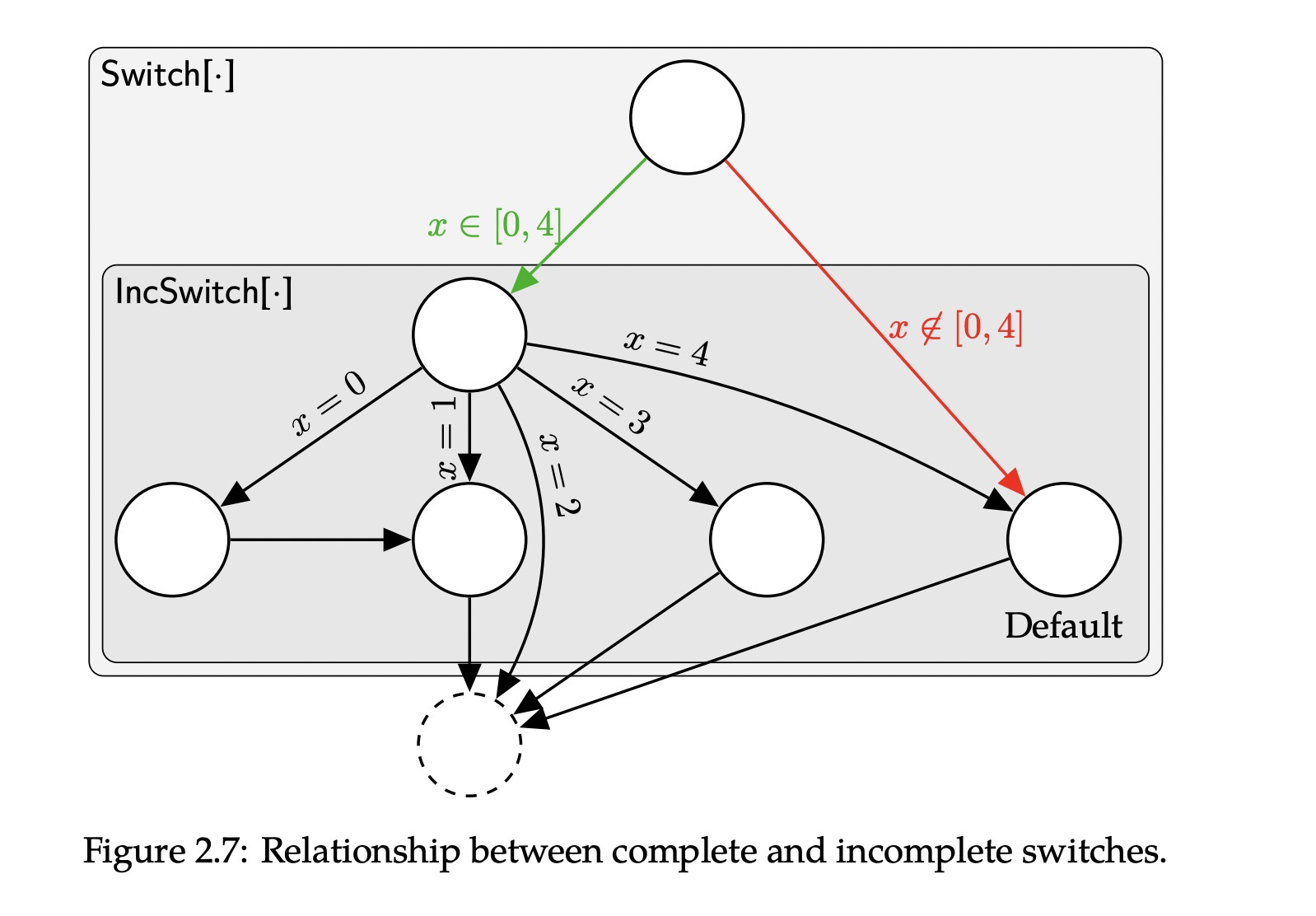
首先明白incomplete 和 complete switch的区别,下图从n出发所有条件
都是相对立的,即完整的switch为 ,不完整的switch则相反。 switch 匹配策略:
通过refined 虚拟化所有指向switch 头后面的节点。
确保switch里面的node都有相同的后继节点:如果switch头节点的immediate post-dominator是所有case节点的后继,那么这个节点就是switch的 fall through后继。
switch的fall through的后继满足三个条件:
- 首先是所有case节点的后继
- 不是case节点本身
- 这个节点有最多的来case节点的入度边。
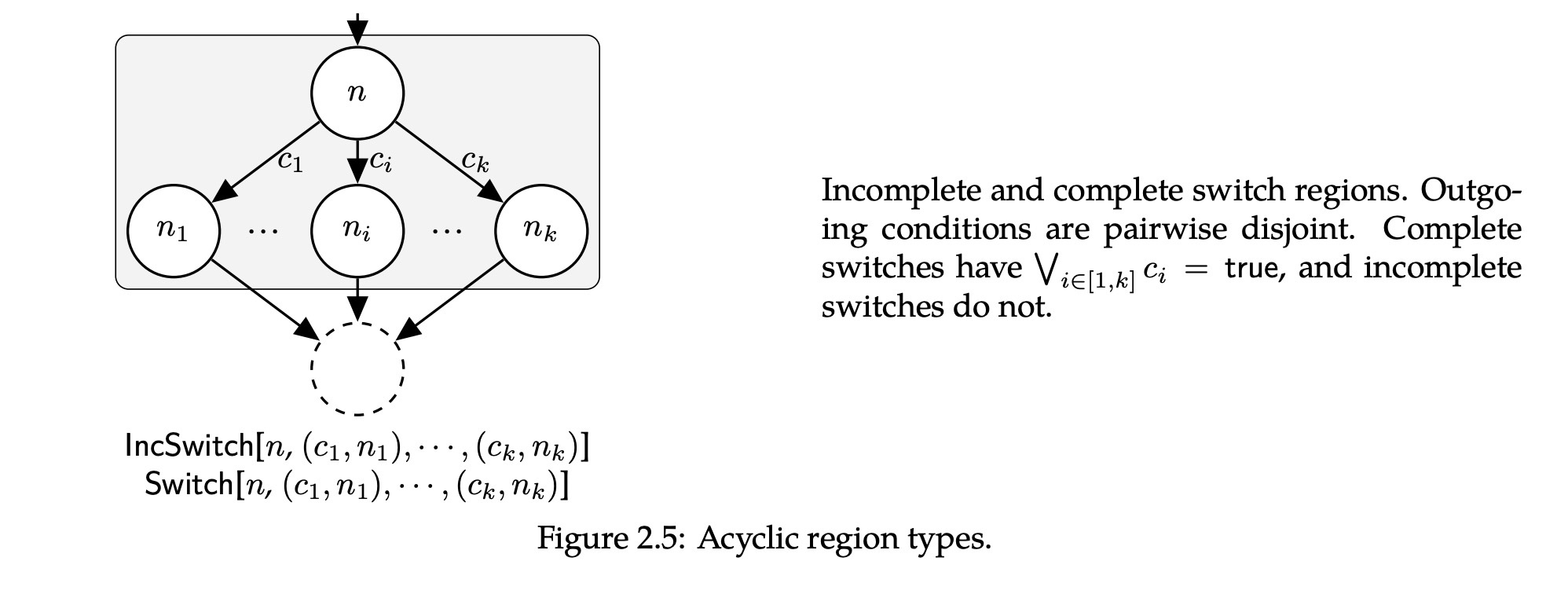
switch candidate(候选):通常先匹配IncSwitch,一个通常策略是switch的cases分为jump table 和default。
环区域
如何在节点n处区别不同的循环结构:通过找指向n的后向边,每一条后向边
可以定义一个循环体,循环体的节点包括那些可以不通过节点n就能到达 的所有节点。(其中n为循环头)先优化处理拥有比较小的循环体的循环结构,来优先匹配更大的循环体(因为没有针对嵌套循环的策略)。 三种不同类型的循环结构:(主要条件判断时机)
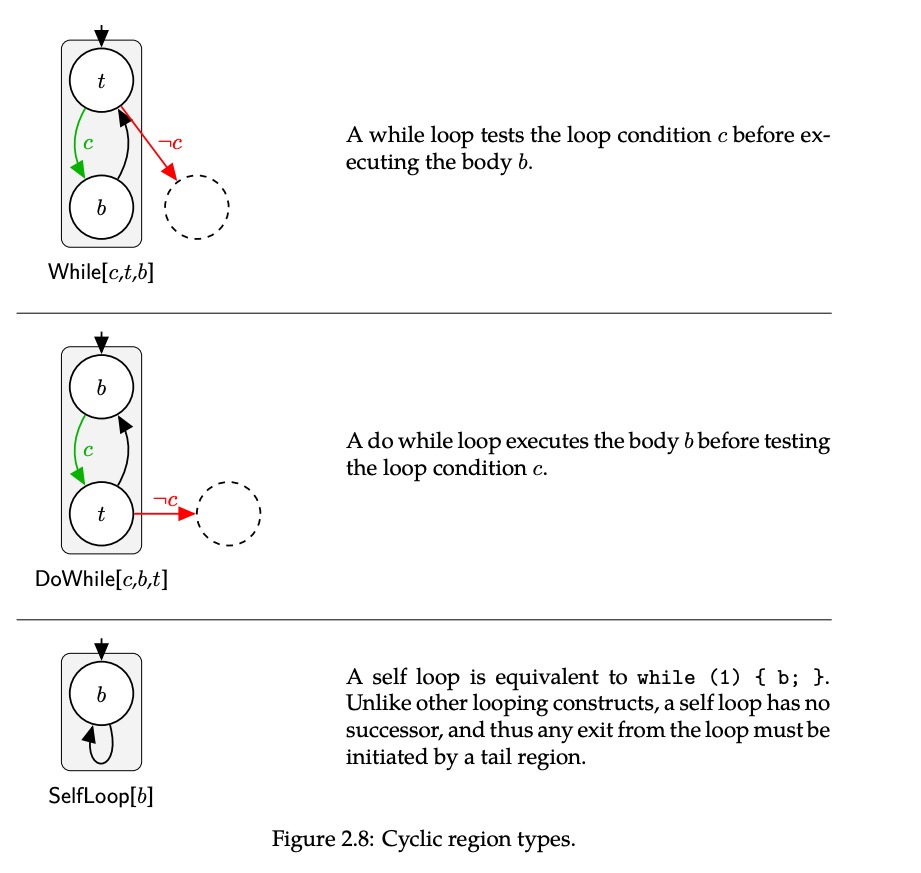
特殊的SelfLoop: (可能在c语言里面的呈现形式)

但是在结构匹配的时候,可以看到selfloop是没有exit边的,这是可以通过虚拟边做到的,也就是形成所谓的尾区域,来匹配一些 break,contiune,goto等语法结构。
循环结构精修:
motivation: 如果发现了一个循环头,但是无法匹配任何循环结构,就开始进行循环结构精修。有环区域什么时候会匹配失败一个循环结构:(1 这个区域有多个入口 (2 这个区域有多个出口 (3 循环体无法被折叠。
step1:当有多个入口时,选择有着入度边最多的那个入口为循环头。指向其他入口的边将会被虚拟化
step2: 识别循环结构类型:(1 如果有一条exit边从循环体出来,则 循环结构为while (2 如果有循环结构后向边的source节点有一条出度边,则循环结构为dowhile (3 否则,只要有exit边,则循环结构为selfloop。 exit边用于确定循环结构的后继节点,反过来后继节点也可以确定循环结构保护了那些节点。
break /contiune:指向循环头的边 用contiune 尾区域来表示。指向循环结构后继节点的边用break 区域来表示,其他所有的虚拟边将变成goto。
精修和非精修的区别:精修在于减少goto的。

step3: 去掉所有影响循环体折叠的边,eg:有一个goto指向了循环体的内部
最后的排序精修
Motivation :当一次迭代过程结束时,如果cfg中的没有一个节点可以被结构化,此时会尝试去掉cfg中的一些边,直到某些节点可以进行结构化。这个过程具有最小的优先级。
去掉边的策略:在dominator tree上进行,优先去掉
- A--->B ,存在从entry可以不通过A到达B的点。
- A--->B, A点到exit只能通过B的边。
这个策略我没太看懂,我觉得需要从大量例子来总结这样的修剪策略
Ceneral Abstractions
Gadget Abstractions
- 源代码抽象的不足:
- 源代码抽象不能表示所有二进制的语义
- 源代码抽象不能表示一个二进制的所有行为
- 隐藏源代码的实际行为,导致一些细节无法被发现,eg: undefined behaviors
- 一些难以抽象的程序行为
- get_pc_chunk 返回一个程序计数器的值
- 代码混淆
- 编译器优化,eg: inline function (高度优化的程序,可能运行更快但是分析越慢)
- general abstractions: 指在所有二进制里面都可以适用的抽象。
- gadget abstraction:gadget 指程序片段,并不需要具体的语义。
- 源代码抽象的不足:
rop的自动构造:
- gadget 收集
- gadget 抽象
- gadget 分配
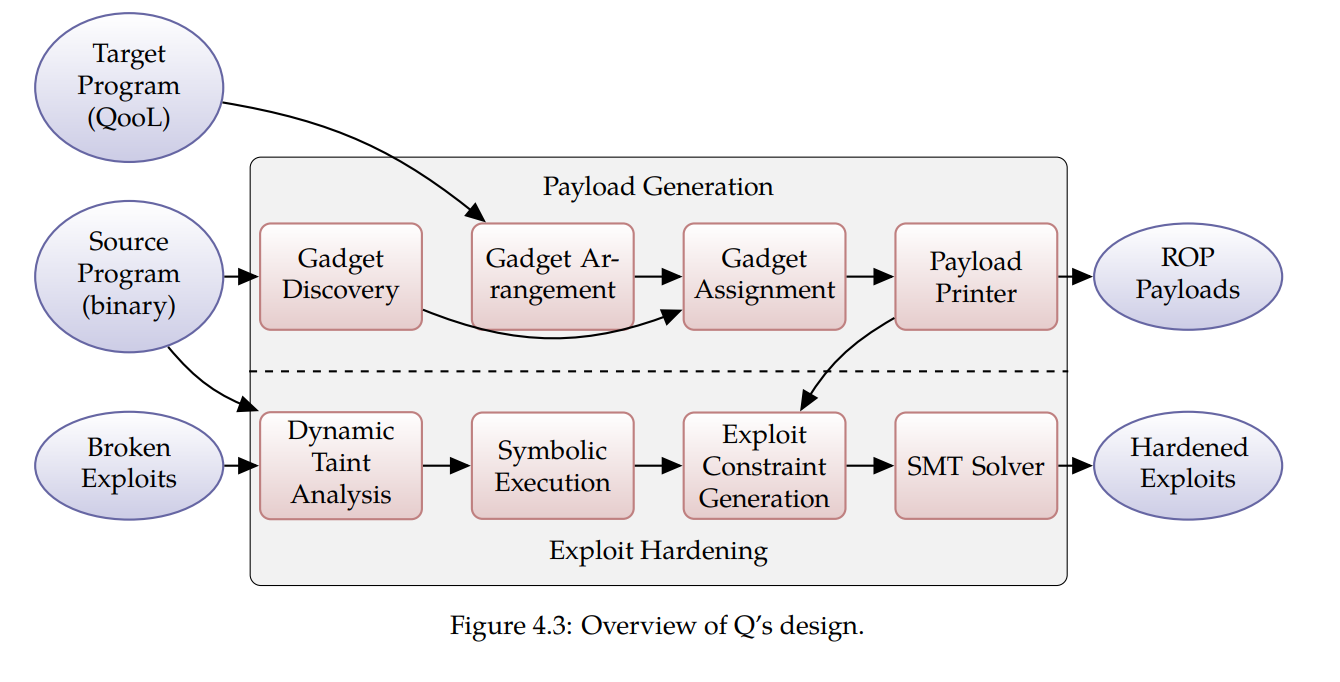
图上的Qool是面对gadget设计的一种高层次的语言,可以这样理解,c complier是为了把c语言翻译成可以运行的二进制,Qool可以类比,需要利用gadgets来实现运行我们的目标”程序“,Qool就是这样一种可以让你在高层次来进行编写自定义的程序,最后帮你翻译成gadgets的形式。在高层次编写的时候,你不需要关注gadget的类型和具体指令。c compiler可以使用所有汇编指令,但是Qool就只能使用提前收集好的gadgets。下面是Qool其中的语法:

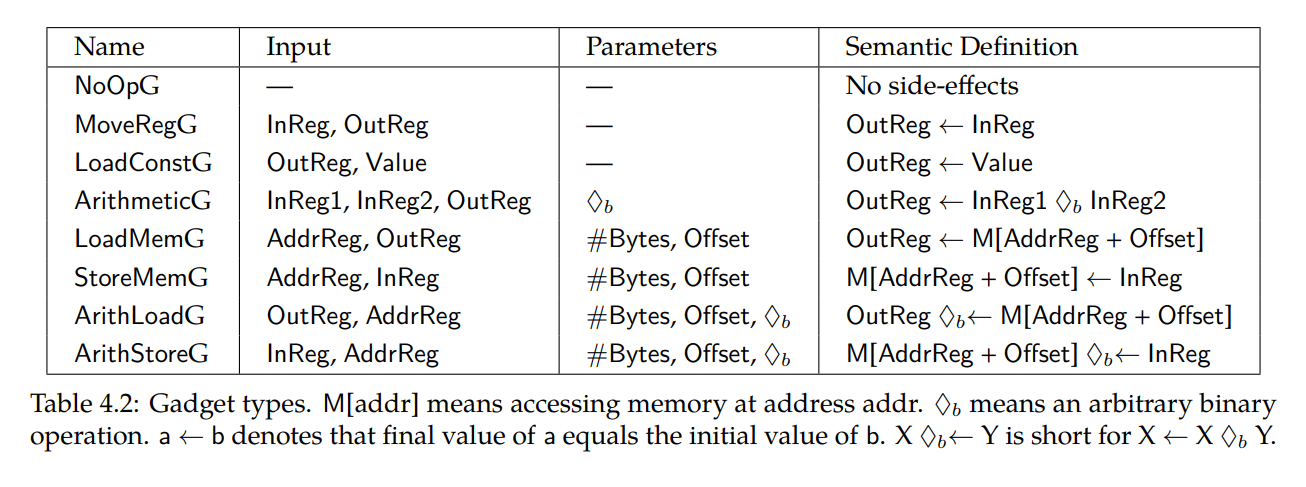
还需要一些关于gadget 类型的定义:
通过Qool可以翻译成下面形式的语法树: