小叙
在之前文章中最后的结尾,我贴了一段代码,不知道有没有师傅遇上了那种情况,因为这其中影响它出现的因素有很多,略微的变化有可能输出的结果就截然不同,为了更好的解释这其中的为什么,我重新从php5的编译器看起,因为之前我一直看的是php7,而php5和php7有很多不一样,比如底层zval结构的变化,php7语法分析过程中生成间接的语法树,执行器handler调度的多种方式,为了让写出来的东西更加的严谨和细致,我看了很多关于本文之外php5其他方面的东西,这是本文迟迟没有写的原因。
回到本文主题,确实这里算是一块php内核中比较庞大的一块内容,从文章的题目也可以猜测到后面的一切内容都关系到了内存,废话不多说进入正题。
简要分析
我把之前遗留问题的代码贴上来: 1
2
3
4
5
6
7
8$a="phpinfo();";
$b=$a;
$serialized_string = 'a:1:{i:1;C:11:"ArrayObject":37:{x:i:0;a:2:{i:1;R:4;i:2;r:1;};m:a:0:{}}}';
$outer_array = unserialize($serialized_string);
gc_collect_cycles();
$filler1 = "aaaa";
$filler2 = &$a;
var_dump($outer_array);$filler2 = &$a;这一步的分裂过程应该是可以拿到$outer_array指向已经被释放的zval结构大小的内存。但是奇怪的是输出$outer_array还是NULL。
为了更好的让师傅了解整个过程,讲一下之前没有提到的,为什么还存在$filler1 = "aaaa"这个赋值过程,在语法分析过程中,通常存在着一个叫三地址中间代码,什么叫三地址呢?比如:x = y op z ,其中op是一个二目运算符, y 和 z是运算分量的地址,也是我们经常说的曹操作数,而x是运算结果存放的地址。这种三地址指令最多只执行一个运算,操作对象也是最基础的地址,叫三地址其实并非会完全用到x y z三个地址,但是至少有一个。
比如$outer_array = unserialize($serialized_string);这一步我们尝试用三地址代码思想来分解一下: 1
2
3send_var $serialized_string //第一步函数传参: op=send_var,y=$serialized_string
$tmp = do_fcall 'unserialize' //第二步函数调用: op=do_fcall,x=$tmp,y='unserialize'
$outer_array assign $tmp //第三步赋值:op=assign,y=$outer_array,z=$tmp
我们再来来看一下gc_collect_cycles();这一步如果用三地址代码来分解的话: 1
do_fcall 'gc_collect_cycles'
send_var opcode来完成参数调用的。但是在php的函数调用里面,无论是否会用到他们的返回值,这个时候都会先初始化一个$tmp,用来保存函数返回值,如果该返回值并没有用到的话,再进行释放,$tmp保存结构同样是zval,所以这里会释放掉一个zval大小的内存。 1
$tmp = do_fcall 'gc_collect_cycles'
$tmp以后zval内存块就刚好'盖'在原先gc释放以外释放掉的\(out_array上面。这里用了一个比较形象的'盖'字,所以这里我们需要先把`\)tmp`拿走,再申请zval的时候就可以拿到$out_array指向的zval。
出现这种奇怪的现象,第一感觉可能在复制分裂申请zval之前,$out_array这个目标zval已经被拿走了,那么是被'谁'拿走了呢?
具体分析
在我拿gdb调之前,我做了一些细微操作,\(out_array却正常输出了,比如新增一条语句:`\)randman="unit"或者把上面的var_dump换成echo`,都能正常输出,是不是感觉非常的不可思议,并且难以理解。
我们进一步缩小问题,当我把简单把var_dump换成了echo, 这是最后一步肯定对面执行过程没有干扰的,但是还是影响了输出,如果说执行过程没有影响,那么最后的不同地方就发生在php代码的编译阶段!
现在我们需要确保一下$out_array释放伴随着gc正常释放了,这时候就需要用gdb来动态调了,第一次断在gc_collect_cycles其中的: 1
2
3
4
5
6
7/* Free zvals */
p = GC_G(free_list);
while (p != FREE_LIST_END) {
q = p->u.next;
FREE_ZVAL_EX(&p->z);
p = q;
}1
2
3
4
5
6
7
8GC buffer content:
[0x7ffff7c828b0] (refcount=2) array(1): {
1 => [0x7ffff7c82aa8] (refcount=1) object(ArrayObject) #1 //ArrayObject
} //outer_array
[0x7ffff7c818e0] (refcount=2,is_ref) array(2): {
1 => [0x7ffff7c818e0] (refcount=2,is_ref) array(2):
2 => [0x7ffff7c828b0] (refcount=2) array(1):
}//inner_array
确保了释放的过程,再来看之后的分配过程,这里可以在_emalloc下个断,预想其过程,$filler1= 'aaaa'拿走了gc_collect_cycles释放的$tmp, 在这过程gdb 一直continue即可,第二个zval的申请确实发生在了引用复制分裂的过程中,但是申请到的内存却是之前ArrayObject对应的zval,这过程中也没有其他操作申请了zval,可out_array对应的zval去哪了呢?
之前dumpgc里面还有outer_array的地址,查看其内容,这里有一个tip,因为我这里使用的php-5.6.20开了debug,开了debug之后,默认把内存保护也开了,内存保护会把释放掉的内存块清零,所以这里我肯定它还在内存池里面。
为什么它还躺在内存池里面呢?引入今天的主角php的内存管理。
php内存管理
玩PWN的师傅都会非常熟悉glibc里面ptmalloc内存模型,同样php里面也有自己的一套内存管理与ptmalloc有些不一样,它和google的tcmalloc是想对应的。这里我画了一张图,我会用图来描述整个过程,拒绝贴代码!
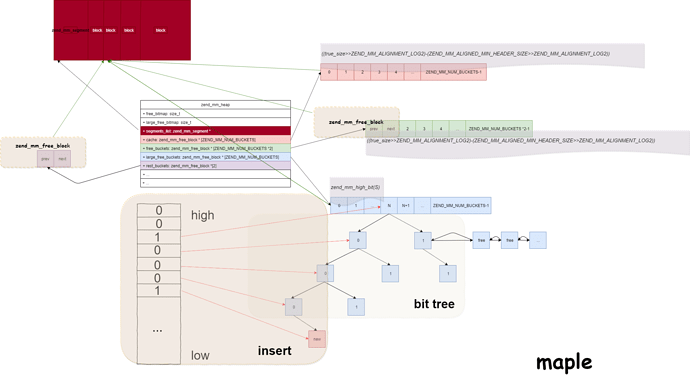 可以看到管理整个内存是一个zend_mm_heap结构,初始化内存可以通过malloc或者mmap来完成,其申请的粒度zend_mm_heap->block来决定的,也就是每次向系统申请的内存大小是zend_mm_heap->block的整数倍
可以看到管理整个内存是一个zend_mm_heap结构,初始化内存可以通过malloc或者mmap来完成,其申请的粒度zend_mm_heap->block来决定的,也就是每次向系统申请的内存大小是zend_mm_heap->block的整数倍
每次向系统申请的内存,都会通过一个zend_mm_segment结构来管理,向系统的申请内存我们称之为segment段,想系统申请的segments,zend_mm_heap->segments_list这个字段组成了一个链表。可以看到segment起始位置保存着zend_mm_segment的结构,而后的位置被分成了一个又一个的block块,看绿箭头的位置,这里blocks来自于4种不同的结构上。我们就这四个结构来分别描述一下:
1.cache:
cache是第一层的缓存结构,可以看到长度是ZEND_MM_NUM_BUCKETS,上面还有一串宏用来计算不同大小的内存块对应的cache里面的index。 cache里面内存块可用的大小为8 * index,最小是可以为0,而最大是8*(ZEND_MM_NUM_BUCKETS-1),这里为什么有一个0呢,因为这里并不是真实可用内存为0。
一个block块某一时刻只有一种状态要么是unused ,要么是used,php里面用两种header结构来分别管理这两种内存,一个是zend_mm_block对应着used状态下的block,另一个是zend_mm_free_block对应着unused状态下的block,used的状态下header只需要记录这block的位置和大小,可能还有debug信息,而unused状态下的header需要额外记录他可能存在于其他4种block管理结构中的位置,开了内存保护以后还会在zend_mm_block后面设置一个魔数,所以这里为了保证两种状态下header大小都够用,我们取两者的最大值: 1
2
3
4ZEND_MM_ALIGNED_FREE_HEADER_SIZE更大一些话,当申请的内存大小介于 ZEND_MM_ALIGNED_MIN_HEADER_SIZE-(ZEND_MM_ALIGNED_HEADER_SIZE+END_MAGIC_SIZE)):0之间的话,那么只需要分配一个header即可,所以就出现了cache里面index为0的可能,当然了其真实可用的内存也不是为0。
总结cache是一个提供快速缓存的不同大小,但是block的大小较小一张单链表,遵循LIFO结构,即后进去先出来。
2.free_buckets:
你可以从图中看到,它的长度是ZEND_MM_NUM_BUCKETS*2,这个结构和ptmalloc里面的bins是一样的,因为在使用zend_mm_free_block只会使用到prev 和 next两个字段,所以这里的free_buckets[index] 和 free_buckets[index+1]分别对应着prev和next,看图我圈了一个zend_mm_free_block结构出来,在初始化的时候prev和next都会指向这个zend_mm_free_block,他储存的size大小对应这cache里面size。相同size组成一张双链表,同样遵循LIFO结构。 其中也使用了bitmap来避免遍历空洞。
3.large_buckets:
这个结构是一个比较有意思的结构,是键树和双链表的结合。看图,index对应着block二进制置1的最高位,这并不是完整的键树,并不是说为其二进制的每一个位都建立结点,而是每一个键树的结点都是一个block,插入的时候只是在已经存在的结点下往下衍生建立新结点。
相同size之间用一条双链表建立起来,可以看图中就形成了相当于二叉树和双链表联合的结构,我还画了一下insert的过程,可以对应着看一下。同样这里也有一个bitmap来避免空洞,其中还有查找和删除过程也值得一看,查找的过程还是遵循最小内存原则,而删除过程会把内存大的结点往root上靠。具体的代码注释,我已经上传到github,有兴趣的师傅们可以去看看。在这里我不想贴代码!
4.rest_buckets:
看名字这里存储着内存块分割留下的剩余的size,这里避免这些剩余的无意义的内存块重新插入free_buckets带来的性能问题。可以看到rest_buckets长度为2,一般情况下遍历查找rest_buckets的时候,只会用到rest_buckets[0],但是当rest_buckets满了以后会通过rest_buckets[1]从最前面把内存块重新释放到free_buckets中,同样着两个长度的zend_mm_block* 也对应着prev和next,和前面的free_buckets一样。
问题所在
现在的你应该对整个php的内存管理也有一个基本的认识。接着我们再来看问题,如果说连续内存申请,都没有拿到$out_array指向的zval内存block,这里不应该用zval,因为在php5里面我在前面说过,申请的应该是zval_gc_info结构,所以这里只有一个原因: $out_array指向的内存块,没有在ZEND_MM_TRUE_SIZE(sizeof(zval_gc_info))内存块大小对应在cache里面的位置的单链表里面。
发生这个问题只有一个原因,那就是在第一次申请$out_array的时候,拿到的内存块的大小要大于ZEND_MM_TRUE_SIZE(sizeof(zval_gc_info)),所以在释放的时候,没有放到预期的cache[index]里面。
为什么会申请到大于ZEND_MM_TRUE_SIZE(sizeof(zval_gc_info))的内存块,这个问题其实也很好理解,如果第一次在申请内存的时候,cache里面没有找到的话,那么接着会去free_buckets里面找,而且比较巧的是free_buckets里面也没有正好符合其大小的blocks,根据bitmap往后找,所以这里有一个内存分割过程,分割出来我们需要的size,然后剩下size,又比较巧,它是小于一块block_header大小的内存,那么这时候会干脆把着剩余的一块都给申请的对象。
所以拿到的block要比预期的要稍微大一点,有的师傅可能会像难道不是$out_array释放的时候产生了合并的情况,其实也是有可能的,当cache满了以后,确实会在把这块内存插入free_buckets之前尝试合并。但是这里情况是前面一种,因为这里的代码量是比较少的,对应的内存开销是比较小的。
再回到之前把var_dump替换为echo的时候发生的奇怪现象。现在可以预想到肯定是内存操作有差异,确实是如此,这需要追溯到语法分析的过程中,var_dump是内部函数的调用而echo只是语法结构,这其中有很多内存操作都有差异,涉及到一些内存的申请和释放,比如调用函数的时候会dup函数名到小写字符,还有编译时刻函数栈结构申请的入栈操作和出栈操作,这过程都会额外产生很多粒度内存块,我并不是指这个过程是随机不可预测,它是可以一步一步推出来的,哪一步申请了内存,那一步释放了内存。这过程是清晰的。
如何解决
还有可能php版本不一样可能也存在一些内存差异的操作,为了能避免这些情况,当然你也随意的改代码,看其是不是正常的输出。更好的做法是在$outer_array对应zval申请的时候,我们让cache里面有其对应的block,怎么做呢?
很简单,我们额外再定义一些php变量再将其unset掉,让其填充cache。如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$a="phpinfo();";
$b = $a;
$serialized_string = 'a:1:{i:1;C:11:"ArrayObject":37:{x:i:0;a:2:{i:1;R:4;i:2;r:1;};m:a:0:{}}}';
$maple = "unit";
$laura = "unit";
$family="unit";
$brother="unit";
unset($maple);
unset($laura);
unset($family);
unset($brother);
$outer_array = unserialize($serialized_string);
gc_collect_cycles();
$filler1 = "aaaa";
$filler2 = &$a;
var_dump($outer_array);
感
我之前也喜欢写一些源码分析之类的文章,但渐渐发觉从源码出发虽然能够探究实现的细节,但这些东西更适合作为自己的学习笔记,如果要讲给别人,还是用一些更加可读的方式比较好。所以我在慢慢改变自己写东西的方式,尽量少贴代码,多用图,把数据结构和数据结构关系阐明更形象一点,用比较简洁的语言来描写调用过程。这个系列写了一些文章了,为什么我会写这些文章,一直没有一个机会说,因为我的二进制起始于php,php这个语言再我来看来是比较成功一门语言,他做到了简单易用,功能也比较丰富,他肩负和完成了自己的使命,以至于很多web选手的第一们语言就是它,未来我想php应该会向java靠拢,并不是说java有多么好,而是这是一种趋势,比如java的jar,未来php可能也会把opcode生成这样一种中间代码。
二进制起始于php,我想给它做点什么,鸟哥是我偶像!!!就像我要给php一个深深的拥抱,一切难以言语的东西都在这个拥抱里面。php内核并没那么生涩,如果纯粹讲的话,确实比较枯燥,像这样由一个又一个的问题引出细节,就是一种非常好的方式,在这过程中很多时候自己也是先学现卖,其中可能存在很多错误,也欢迎师傅指出来,至于未来这个系列会走到哪一步我也不知道。。。
我想它应该有它存在的价值!